

Un Proof of Concept (PoC) évolutif de l'IA est un projet expérimental qui démontre la viabilité d'une solution d'IA, intégrant la prospective architecturale et les considérations d'infrastructure nécessaires à l'expansion future d'un système de production complet. Il vérifie le potentiel d'un modèle d'IA tout en jetant les bases d'un déploiement dans le monde réel.
Un PoC IA évolutif consiste à prouver qu'il peut fonctionner à grande échelle, fournir une valeur constante et s'intégrer parfaitement aux processus métier existants. Il transforme le potentiel théorique en solutions tangibles et déployables qui stimulent la croissance et l'efficacité. De nombreuses entreprises recherchent une solution complète Solutions d'IA pour les entreprises qui sont à la fois innovants et pratiques pour les applications à grande échelle.
Un PoC IA véritablement évolutif est conçu dans une optique de production dès le premier jour. Cela implique de prendre en compte des facteurs tels que le volume de données, la vitesse de traitement, la fréquence de reconversion des modèles, les environnements de déploiement et les points d'intégration avec d'autres systèmes. Il s'agit de construire une base solide capable de supporter une charge et une complexité accrues sans nécessiter une reconstruction complète par la suite.
Un prototype standard se concentre souvent uniquement sur la démonstration des fonctionnalités de base en utilisant des données et des ressources limitées, souvent dans un environnement isolé. C'est un moyen rapide, simple et efficace de tester une idée. Un PoC évolutif va toutefois plus loin. Cela implique :
Points clés à emporter : Un PoC d'IA évolutif est un investissement avant-gardiste, qui permet de valider non seulement le « si », mais également le « comment » et « à quel coût » du déploiement de solutions d'IA à grande échelle au sein d'une organisation.
La création d'un pipeline robuste pour l'IA, du PoC à la production, repose sur deux piliers essentiels : la conception d'une architecture évolutive et la mise en place de pipelines de données résilients. Les négliger dès le début peut entraîner d'importants goulots d'étranglement et entraîner des retouches plus tard.
Pour concevoir une architecture d'IA évolutive, il faut aller au-delà de l'expérience initiale. Cela implique la modularité, les microservices et la conteneurisation.
Étapes réalisables :
Les données sont la pierre angulaire de tout système d'IA. Les pipelines de données résilients garantissent un flux de données continu et de haute qualité à des fins de formation, d'inférence et de surveillance, même en cas de stress ou de défaillance.
Étapes réalisables :
Points clés à emporter : Une solution d'IA prête pour la production nécessite une architecture évolutive basée sur la modularité et les principes du cloud, associée à des pipelines de données automatisés, validés et résilients.

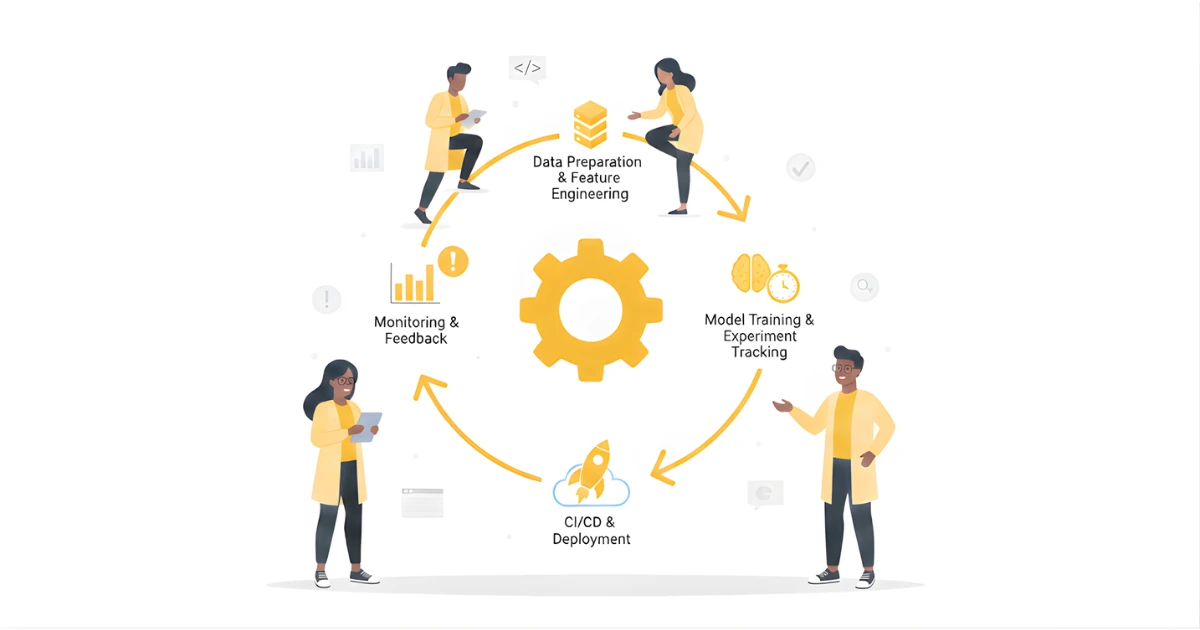
MLOps (Machine Learning Operations) étend les principes DevOps aux flux de travail d'apprentissage automatique, comblant ainsi le fossé entre les data scientists et les équipes opérationnelles. La mise en œuvre des meilleures pratiques MLOps est cruciale pour faire passer les modèles d'IA de la recherche à des systèmes de production fiables. Cela inclut l'intégration continue/le déploiement continu (CI/CD) et une surveillance robuste.
L'application de la CI/CD aux flux de travail ML implique l'automatisation de l'ensemble du processus, des modifications de code au déploiement du modèle et à la reconversion. Cela garantit des mises à jour rapides, cohérentes et fiables.
Étapes réalisables :
Les modèles se dégradent au fil du temps en raison de l'évolution des modèles de données ou de la dynamique du monde réel. La surveillance et l'optimisation continues sont essentielles pour maintenir les performances.
Stratégies réalisables :
Points clés à emporter : Les MLOps, grâce à des pipelines CI/CD automatisés et à une surveillance continue, constituent l'épine dorsale d'une production réussie de modèles d'IA, garantissant que les modèles restent performants et pertinents.
Décider de créer une plateforme MLOps interne ou de tirer parti de services externes est un choix stratégique essentiel lors de la mise à l'échelle de l'IA. Ce dilemme « construire ou acheter » a un impact sur l'allocation des ressources, les délais de mise sur le marché et la maintenabilité à long terme.
La création d'une plateforme MLOps interne offre un maximum de personnalisation et de contrôle, mais elle nécessite beaucoup de ressources.
Envisagez de construire en interne si :
Difficultés : Un investissement initial élevé dans le développement et la maintenance continue, nécessitant une équipe dédiée d'ingénieurs ML, de spécialistes DevOps et d'architectes de données.
Un excellent exemple de stratégie de « construction » réussie est la transformation par Zillow de son emblématique Zestimate outil d'évaluation immobilière.
Les plateformes cloud et les services gérés accélèrent considérablement le développement et le déploiement de l'IA en fournissant une infrastructure et des outils prédéfinis. Ces plateformes éliminent une grande partie de la complexité sous-jacente, permettant aux équipes de se concentrer davantage sur le développement de modèles.
Avantages :
De nombreuses entreprises explorent des partenariats avec Sociétés de conseil en IA pour tirer parti de ces plateformes de manière efficace.
Services PoC d'IA spécialisés, tels que Axiome du nuage imaginaire, sont conçus pour réduire les risques liés aux investissements dans l'IA et créer une voie claire et validée vers la production. L'axiome est prix fixe, 6 semaines processus conçu spécifiquement pour les leaders de l'ingénierie, les directeurs techniques et les décideurs techniques qui ont besoin de valider des initiatives d'IA critiques avant de s'engager dans un développement à grande échelle.
Cette approche « prête à l'emploi » construit le PoC en termes d'évolutivité, de maintenabilité et de sécurité dès le premier jour, évitant ainsi la dette technique liée à un prototype standard.
Comment Axiom accélère votre transition vers l'IA :
Points clés à emporter : La décision « construire ou acheter » dépend de vos besoins uniques, des ressources disponibles et de vos priorités stratégiques. Les plateformes cloud offrent rapidité et évolutivité, tandis qu'un service spécialisé tel qu'Axiom propose un parcours accéléré, sans risques et prêt à l'emploi, du concept à un PoC validé en production.
L'excellence technique ne suffit pas à elle seule à une évolutivité réussie de l'IA. L'alignement organisationnel, la préparation culturelle et des cadres de gouvernance solides sont tout aussi essentiels pour garantir que les solutions d'IA génèrent une valeur commerciale durable.
L'adoption réussie de l'IA nécessite l'adhésion de l'ensemble de l'organisation, des cadres aux employés de première ligne. La promotion d'une culture « prête à l'IA » implique la communication, l'éducation et la collaboration.
Étapes réalisables :
À mesure que l'IA évolue, ses impacts potentiels augmentent également. L'établissement de directives claires en matière de gouvernance et d'éthique est essentiel pour un déploiement responsable.
Considérations critiques :
Points clés à emporter : Au-delà des détails techniques, le succès de la mise à l'échelle de l'IA repose sur un fort alignement des dirigeants, une culture organisationnelle favorable et des cadres éthiques et de gouvernance proactifs.
La transition d'un modèle d'IA d'un prototype contrôlé vers un environnement de production dynamique présente plusieurs défis complexes. Il est essentiel d'anticiper et de planifier ces obstacles pour une mise à l'échelle fluide et efficace.
Voici quelques-uns des défis les plus courants et les plus critiques en matière d'IA de production :
De nombreux projets d'IA ne parviennent pas à dépasser le stade du laboratoire en raison de quelques pièges récurrents :
Points clés à emporter : La gestion proactive des données et de la dérive des modèles, associée à une approche axée sur la production et à une solide collaboration interfonctionnelle, est essentielle pour surmonter les défis inhérents à la mise à l'échelle de l'IA.
.webp)
La migration d'une preuve de concept basée sur l'IA vers un environnement de production évolutif est un parcours complexe et enrichissant. Cela nécessite un excellent algorithme et un mélange stratégique d'architecture robuste, de pratiques MLOps diligentes, de décisions réfléchies entre la construction et l'achat et d'un alignement organisationnel solide.
En se concentrant sur la mise en œuvre pratique, la surveillance continue et la résolution proactive des défis, les entreprises peuvent exploiter tout le potentiel de leurs initiatives d'IA, transformant ainsi l'innovation en valeur commerciale durable.
Êtes-vous prêt à valider votre vision de l'IA et à réduire les risques liés à votre investissement ?
Le passage du concept à la production est l'étape la plus critique du développement de l'IA. Nous contacter pour savoir comment Service PoC Axiom AI, un engagement à prix fixe de 6 semaines conçu pour permettre aux responsables techniques de tester, de valider et d'élaborer un plan prêt à être mis en production pour leurs initiatives d'IA les plus critiques.
Après un PoC d'IA réussi, les étapes essentielles consistent à affiner le modèle de production, à développer des pipelines de données évolutifs, à configurer des MLOps pour la CI/CD, à concevoir pour la surveillance et la reconversion, et à obtenir l'adhésion des parties prenantes pour un déploiement complet.
Pour déplacer un modèle d'IA d'un Jupyter Notebook vers la production, vous devez d'abord refactoriser le code du bloc-notes en scripts modulaires adaptés à la production. Ensuite, conteneurisez le modèle et ses dépendances (par exemple, avec Docker), implémentez le contrôle de version, intégrez-le aux pipelines CI/CD et déployez-le sur une infrastructure évolutive, telle qu'un service géré dans le cloud ou un cluster Kubernetes.
Une liste de contrôle pour réussir la production de modèles d'IA inclut généralement : garantir la qualité et la disponibilité des données, concevoir une architecture évolutive, implémenter MLOps CI/CD, établir une surveillance continue de la dérive et des performances, configurer une reconversion automatisée, sécuriser l'infrastructure, répondre aux préoccupations éthiques et de gouvernance, et planifier l'intégration commerciale et l'adoption par les utilisateurs.
Un service MLOps géré fournit des plateformes prêtes à l'emploi et une assistance experte, gérant l'infrastructure, les outils et les meilleures pratiques, ce qui accélère le déploiement et réduit la charge opérationnelle. La création d'une solution interne nécessite des investissements importants dans le développement et la maintenance de votre propre plateforme, offrant une personnalisation maximale mais nécessitant une expertise et des ressources internes importantes.


Alexandra Mendes est spécialiste senior de la croissance chez Imaginary Cloud et possède plus de 3 ans d'expérience dans la rédaction de textes sur le développement de logiciels, l'IA et la transformation numérique. Après avoir suivi un cours de développement frontend, Alexandra a acquis des compétences pratiques en matière de codage et travaille désormais en étroite collaboration avec les équipes techniques. Passionnée par la façon dont les nouvelles technologies façonnent les entreprises et la société, Alexandra aime transformer des sujets complexes en contenus clairs et utiles pour les décideurs.
People who read this post, also found these interesting:










-%20Survey%20Insights.webp)



.webp)

.webp)

.webp)
.webp)










.webp)
.webp)
.webp)



.webp)

.webp)



.webp)


%20(1).webp)
.webp)


.webp)


.webp)
.webp)





.webp)













































