

Denna rapport analyserar kundrecensionerna av Britannia International Hotel Canary Wharf. Analysen utfördes med hjälp av Natural Language Processing tekniker, och resultaten användes för att identifiera vilka aspekter av hotellets service som behövde förbättras.
Förutom gästfrihetsindustrin kan denna analys gynna alla andra sektorer med tillgång till kundfeedback, som e-handel, mattjänster eller underhållningsindustrin.
En av de mest kritiska aspekterna av att förstå ett företag är att förstå dess styrkor och svagheter. Att analysera varför det blomstrar eller inte representerar en nyckel till företagets livslängd. Hotell är inte konstigt för detta scenario.
Som företagare är det viktigt att förstå varför vissa kunder kanske inte återvänder till hotellet, orsaken bakom viss motvilja eller vad som positivt stod ut för dem.
För att utföra denna forskning samlade vi en uppsättning hotellrecensioner och fokuserade vår uppmärksamhet på ett specifikt hotell: Britannia International Hotel Canary Wharf.

Den dataset samlades in från Kaggle-plattformen, som innehöll över 515 000 kundrecensioner och poäng på 1493 lyxhotell över hela Europa.
För att få insikter i hotellrecensionerna och förstå kundernas känslor och feedback mer exakt behövde vi förstå kundernas åsikter och segmentering i vår dataset med tillgänglig data.
Dessutom gör den stora mängden kundfeedback det tidskrävande att manuellt granska dem för att fånga kundernas preferenser och smärtpunkter. Därför fortsatte vi också att analysera granskningstexterna med Natural Language Processing -tekniker för att förstå de inneboende känslorna och känslorna bakom recensioner och känna igen vilka aspekter av hotellet som krävde förbättringar.
Medan vi tillämpade denna process på gästfrihetsindustrin, kan denna typ av analys enkelt implementeras för alla andra branscher som fångar feedback från kunder eller till och med aktiveras genom att samla in kundkommentarer från inlägg på sociala medier.
Vi började med att utvärdera tillgängliga data, med särskild uppmärksamhet på formatet och sundheten för varje fält. Som är typiskt när man hanterar datamängder, särskilt sådana som involverar användargenererade data, behövde vissa data rengöras. Detta är ett viktigt steg i varje dataanalysprocess för att säkerställa att de data vi arbetar med och använder som grund för insikter är sunda och därför leder till rimliga och representativa slutsatser.
I det specifika fallet med denna datauppsättning behövde den faktiska granskningstexten lite mindre rengöring för att ta bort överflödigt blanksteg. Men vi märkte också en betydande fråga: alla skiljetecken saknades i granskningen. Därför var det nödvändigt att utföra ett förbehandlingssteg. Vi fortsatte med att återställa en del av strukturen som tillhandahålls av skiljetecknet för att säkerställa att vi kunde använda naturliga språkbehandlingstekniker och få relevanta resultat. En enkel men effektiv metod var att approximera den strukturen genom att lägga till perioder före varje ord som börjar med en stor bokstav.
Effektiviteten av den metoden härrörde också från vår ytterligare bearbetning, där vi filtrerade kända akronymer och namngivna enheter, så vi skulle inte lägga till onödiga perioder. För att uppnå det använde vi automatisk namngiven entitetsigenkänning, en process som försöker identifiera namngivna enheter i en viss text automatiskt. I NLP-sammanhang är namngivna enheter verkliga objekt som kan identifieras med ett riktigt namn, inklusive städer, individer, organisationer etc.
Nästa steg var att skapa vår dataset, som vi filtrerade för att endast gälla för vårt specifika hotell. Med vår filtrering kunde vi få tillgång till information om just vårt hotell.
Datauppsättningen innehåller granskningsdatumet och poängen som ges till den vistelsen. Den hade också information om granskarens nationalitet och taggar som beskrev besökets egenskaper, till exempel om det utgjorde ett dubbel- eller enkelrum och hur lång vistelsen var. Dessutom hade den också negativa och positiva recensioner av den vistelsen.
För att approximera tillgängliga data till ett verkligt scenario maskade vi slumpmässigt de negativa och positiva recensionerna i endast en kolumn för att analysera senare.
Den första uppgiften var att se recensionernas betyg efter datum. Det kan vara möjligt att identifiera perioder där betygen inte skulle vara så bra. Detta kan härröra från en säsongsbetonad aspekt, till exempel att inte ha luftkonditionering på sommaren eller påverkan av en viss anställd.
Detta tillvägagångssätt var inte fruktbart, men samma logik gällde för att analysera taggar eller nationaliteter. Genom taggarna kunde vi till exempel identifiera om kunder med en vistelse i Executive-dubbelrum lämnade dåliga recensioner eller inte. Den visualiseringen kan göras genom boxplot. Vi analyserade alla olika taggar och fann att de flesta av dem återspeglade liknande fördelningar, vilket förhindrar möjligheten att få relevanta insikter.

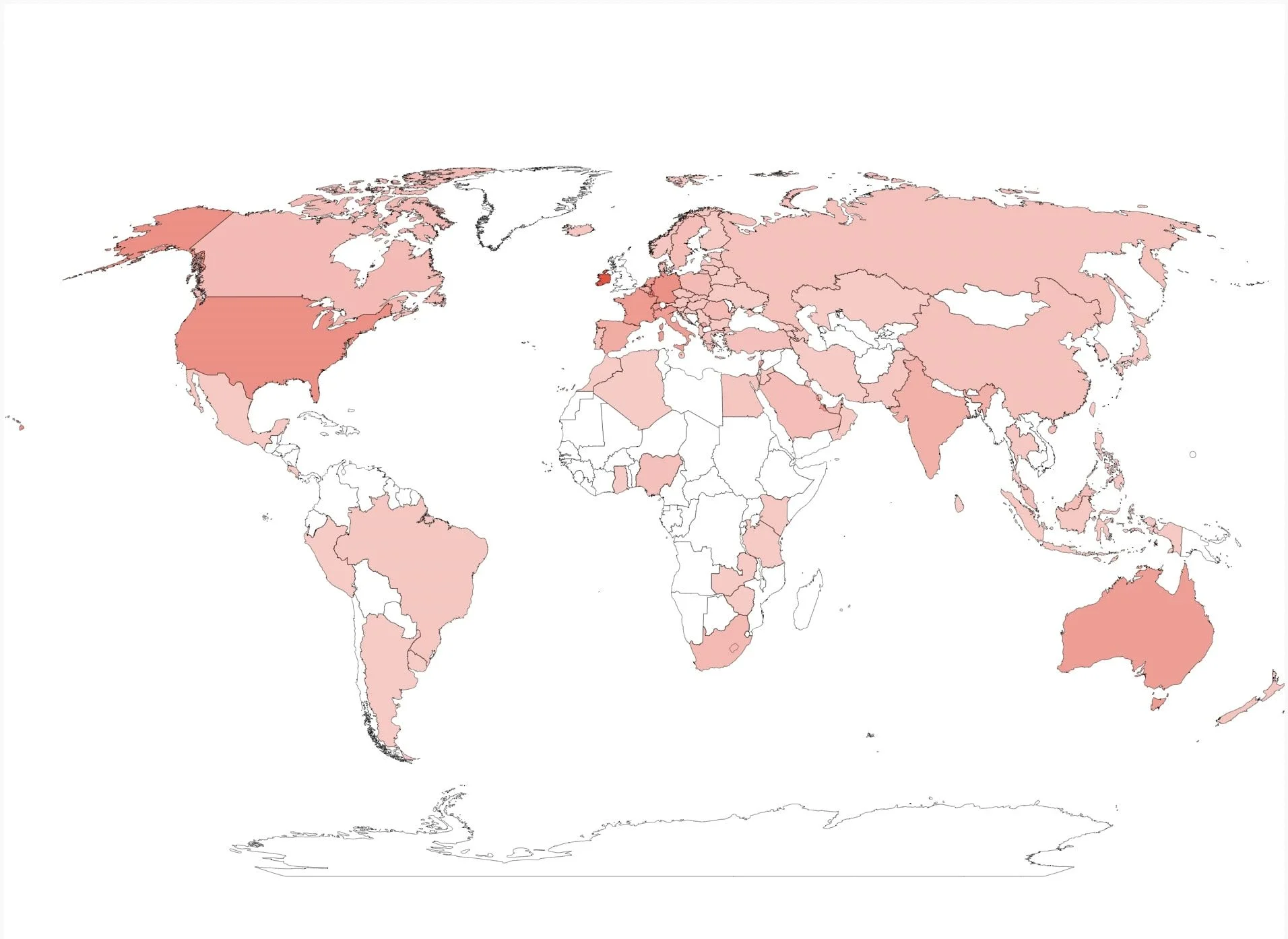
När det gäller nationaliteter var det viktigt att analysera fördelningen av våra kunder. Detta kan ge insikter om marknadsföringsteamets effektivitet på vissa marknader. Exklusive de brittiska kunderna, som representerar 80% av alla kunder, får vi följande världskarta översikt, där mörkare nyanser indikerar ett högre antal granskare från den nationaliteten:
För att ytterligare förstå känslan bakom recensionerna använder vi en språkmodell som finns på HuggingFace-plattformen för att veta om recensionen var positiv eller negativ. Den flerspråkiga XLM-Roberta-Base-modellen tränades på ~ 198M tweets och finjusterades för sentimentanalys. Sentimentfinjusteringen gjordes på 8 språk.
Med förmågan att dela upp recensionerna i positiva och negativa med en rimlig konfidensnivå (0,76 noggrannhet i vår datauppsättning) försökte vi analysera mönster inom dessa recensioner. Ett enkelt sätt att visualisera orden är genom ordmoln. Följande är ordmolnet för negativa och positiva recensioner.


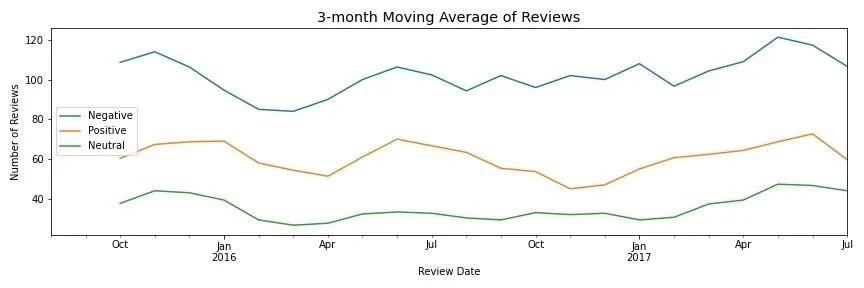
Det finns mycket information att få genom att analysera dynamiken mellan positiva och negativa kundrecensioner. Kunderna vill säkert säga sitt, vilket framgår av vår datamängd, där negativa recensioner i genomsnitt är över dubbelt så långa som positiva recensioner. Genom att titta på utvecklingen av det genomsnittliga antalet recensioner över tid kan vi dessutom se en potentiell liten ökande trend i antalet negativa recensioner, som verksamheten bör vara uppmärksam på.
Förutom att identifiera känslan bakom en text, är en annan teknik i NLP att identifiera känslorna bakom den. För att uppnå detta använde vi NCRlex-biblioteket. NCRlex-biblioteket låter oss känna igen känslor från texter, till exempel rädsla, ilska eller överraskning. Denna analys gör det möjligt för oss att mer exakt förstå hur kunderna tycker om en specifik tjänst eller produkt.
På samma sätt som sentimentvisualisering kan vi visualisera ett ordmoln för varje känsla inom de positiva eller negativa recensionerna genom att identifiera de olika känslorna som är associerade. Till exempel är ordmolnet som genereras från förtroendekänslan inom de positiva recensionerna följande:
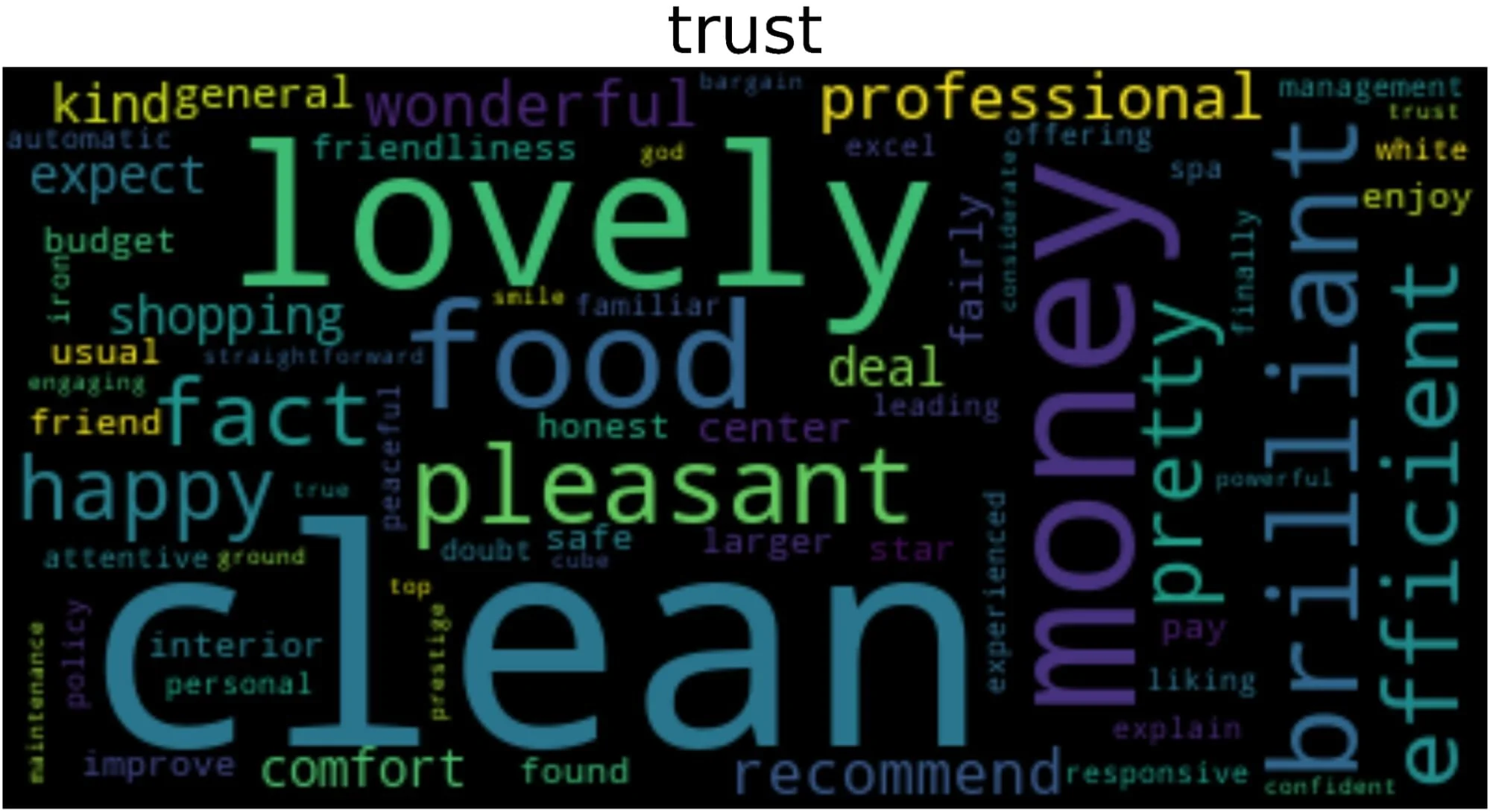
Denna process gör att vi kan få en uppfattning om vad som utlöser vilken kundkänsla.
För att ytterligare analysera recensionerna ville vi identifiera huvudobjekten för kundkommentarer i sina recensioner. För att uppnå det extraherade vi relevanta sökord från uppsättningen positiva och negativa recensioner med hjälp av YAKE, en oövervakad automatisk sökordsextraktionsmetod.
Denna metod beräknar statistiska funktioner relaterade till egenskaper för varje granskning, inklusive ordfall, position, frekvens, sammanhang och vikter för varje term enligt dessa funktioner.
Slutligen beräknas en poäng som indikerar betydelsen av varje term som ett potentiellt nyckelord. Detta är en kraftfull men ändå lätt metod som, på grund av sin helt oövervakade natur, kan användas på olika domäner och även med andra språk.
Dessutom använde vi ett rent frekvensbaserat tillvägagångssätt för att avslöja de vanligaste objekten som nämns i recensioner. Resultaten liknade vår nyckelordsanalys och bekräftade dess giltighet och tillförlitlighet.
Dessa var nyckelorden som identifierades för positiva och negativa recensioner:
Som förväntat är de identifierade nyckelorden vanliga punkter som behandlas i gästfrihetsbranschens recensioner. De utgör redan en bra indikator på adekvat service eller potentiella förbättringsområden för hotellet.
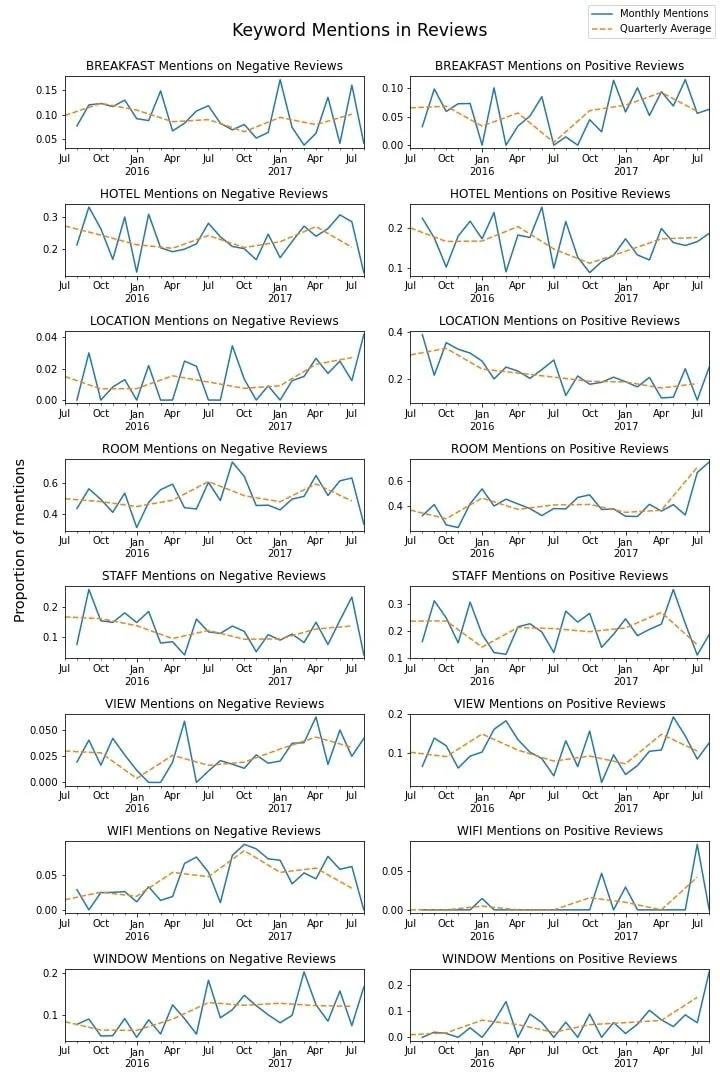
Vi ville dock gå djupare in i analysen och avslöja exakt vad det var med dessa objekt som fungerade - eller inte - fungerade som förväntat av kunderna. Till exempel, varför var fönster en så framträdande aspekt av negativa recensioner?
För detta ändamål använde vi en annan teknik från Natural Language Processing: syntaktisk beroendeanalys. Vi använde SpaCy, ett snabbt, omfattande och produktionsklart NLP-bibliotek för Python, för att skapa ett syntaktiskt beroendeträd, som förbinder alla termer i inmatningstexten enligt deras syntaktiska relation. Sedan frågade vi det här trädet för att fastställa exakt vad det handlade om ett visst sökord (till exempel ”rum” eller ”plats”) som kunderna gillade eller inte särskilt gillade.
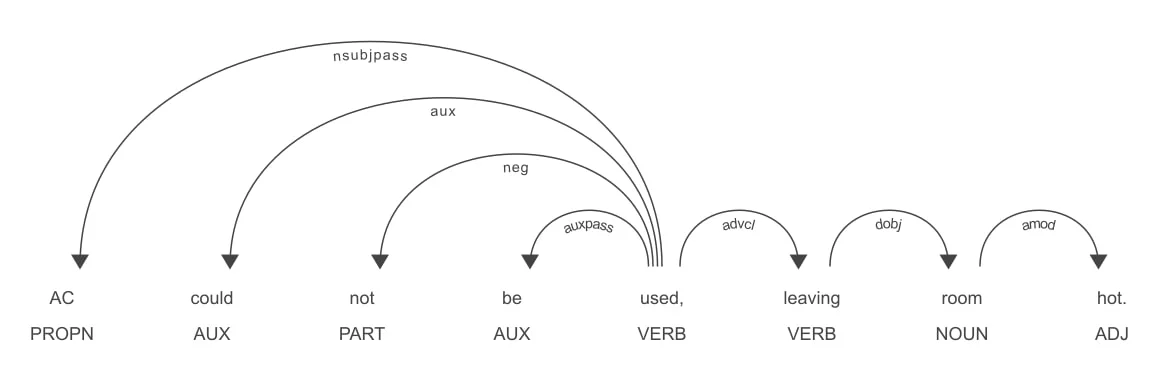
Resultatet blev en lista med modifierare för varje nyckelord. Vi kan till exempel lära oss att kunder kan betrakta ett ”rum” som ”rymligt” eller ”platsen” som ”bekvämt”. Denna resulterande lista med modifierare gjorde det möjligt för oss att skapa ordmoln för att visualisera frekvensen för varje modifierare för det givna nyckelordet, till exempel ordmolnet nedan, för nyckelordet ”rum”:
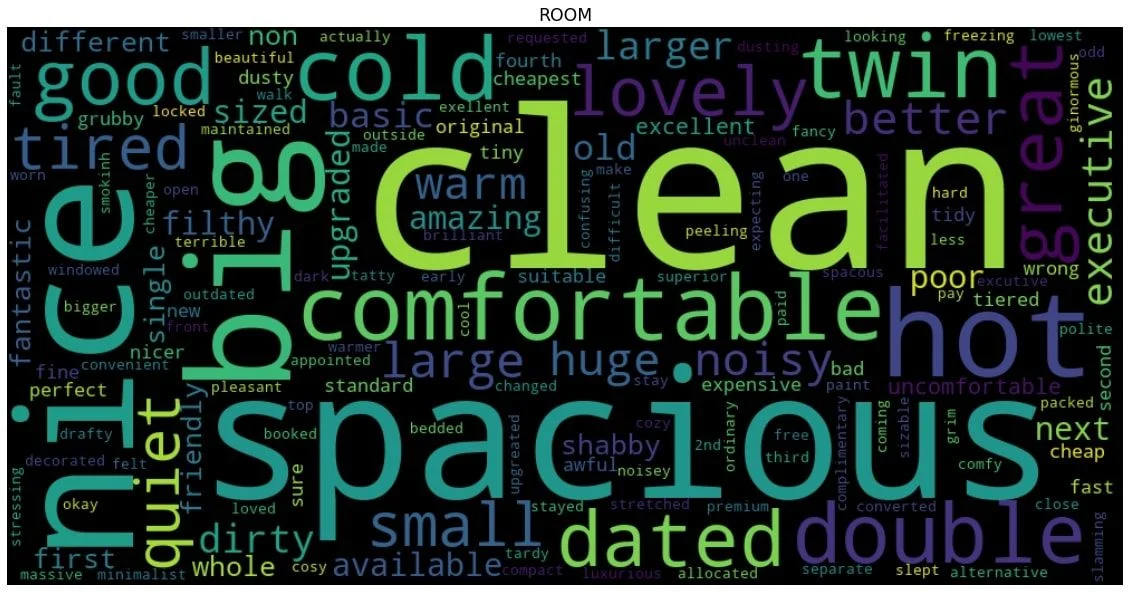
Genom att analysera dessa frekventa modifierare för varje sökord, deras relevans och vikt, och analysera separat för positiva och negativa recensioner, gav oss en djupare inblick i vad kunderna gillar bäst - och inte så mycket - resultaten vi presenterar nedan.

Efter att ha analyserat datamängden enligt beskrivningen ovan kunde vi identifiera några positiva aspekter av verksamheten, liksom viktiga förbättringsområden.
En märkbar kommentar från kunder, som ofta förekommer i både positiva och negativa recensioner, är att vissa anser att hotellet är daterat. De tre huvudmodifierarna som används för att beskriva hotellet i negativa recensioner avser den kvaliteten. Detta tyder på att företaget kanske vill undersöka renovering för att lugna dessa smärtpunkter.
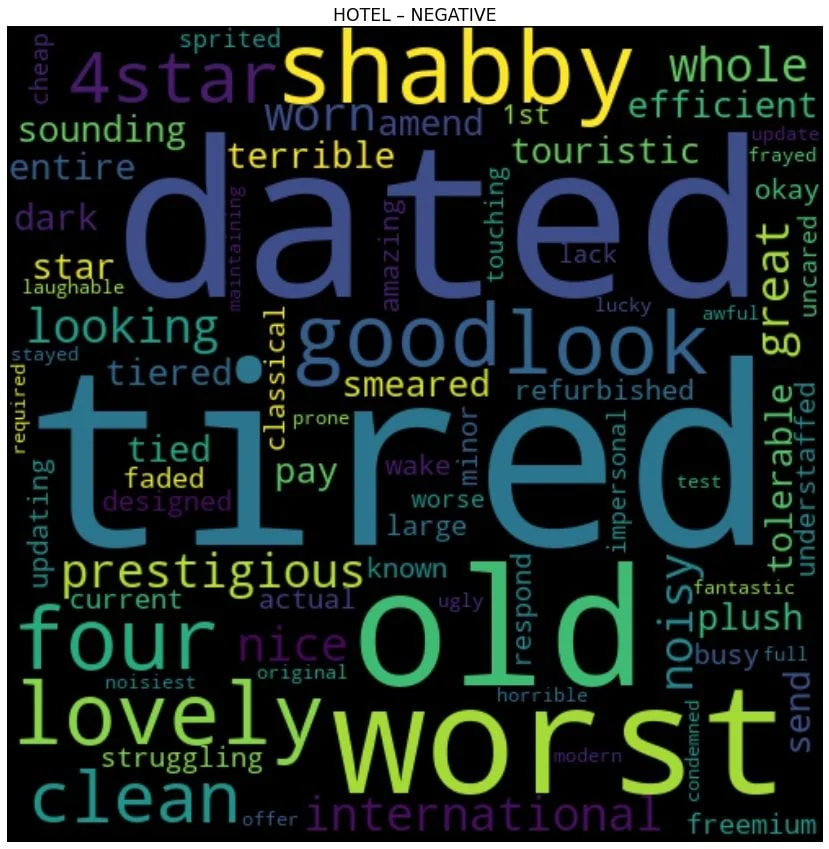
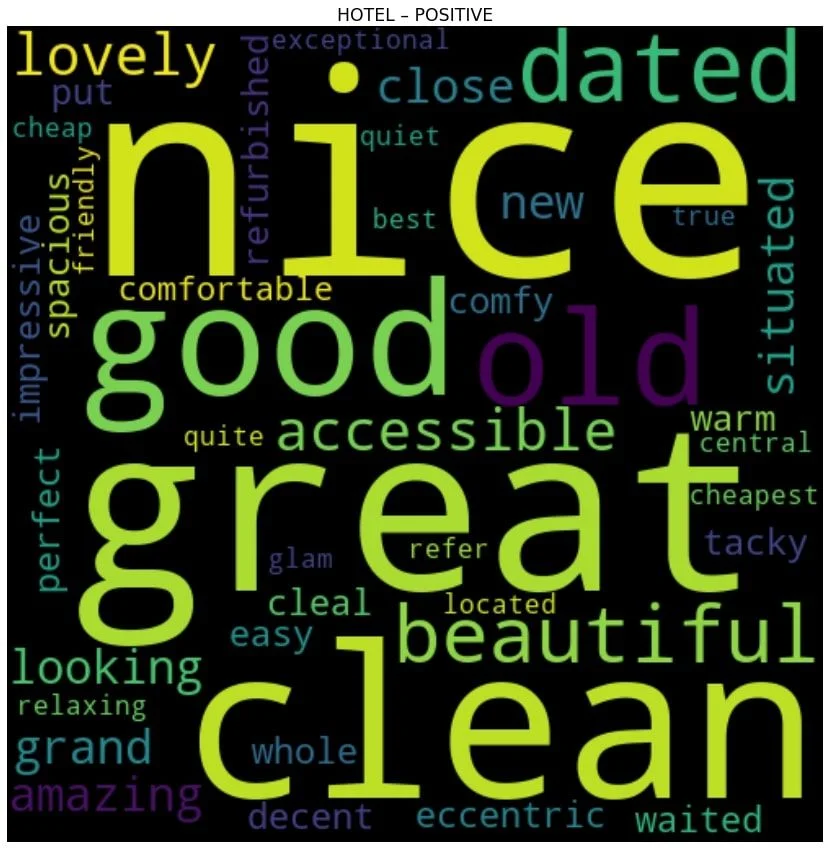
Sökordsanalysen avslöjar kundernas vanligaste punkter när de publicerar sina recensioner. Som man kan förvänta sig har rummet en framträdande plats i både negativa och positiva recensioner. Även om det nämns regelbundet i negativa recensioner under den period vi analyserade, var det under ungefär de senaste sex månaderna en ökning av rumsomnämnanden i positiva recensioner, en potentiellt gynnsam trend som verksamheten bör vara medveten om. I positiva recensioner hänvisar de vanligaste kommentarerna till rum som rena och rymliga. Det finns också referenser till att vara övergripande bekväm och billig.
Sängarna nämndes också ofta, med vissa användare som ansåg dem styva och obekväma. Förekomsten av denna kommentar föreslår också ett omedelbart förbättringsområde. På den noten påpekade vissa kunder också att de tyckte att hotellet var bullrigt.
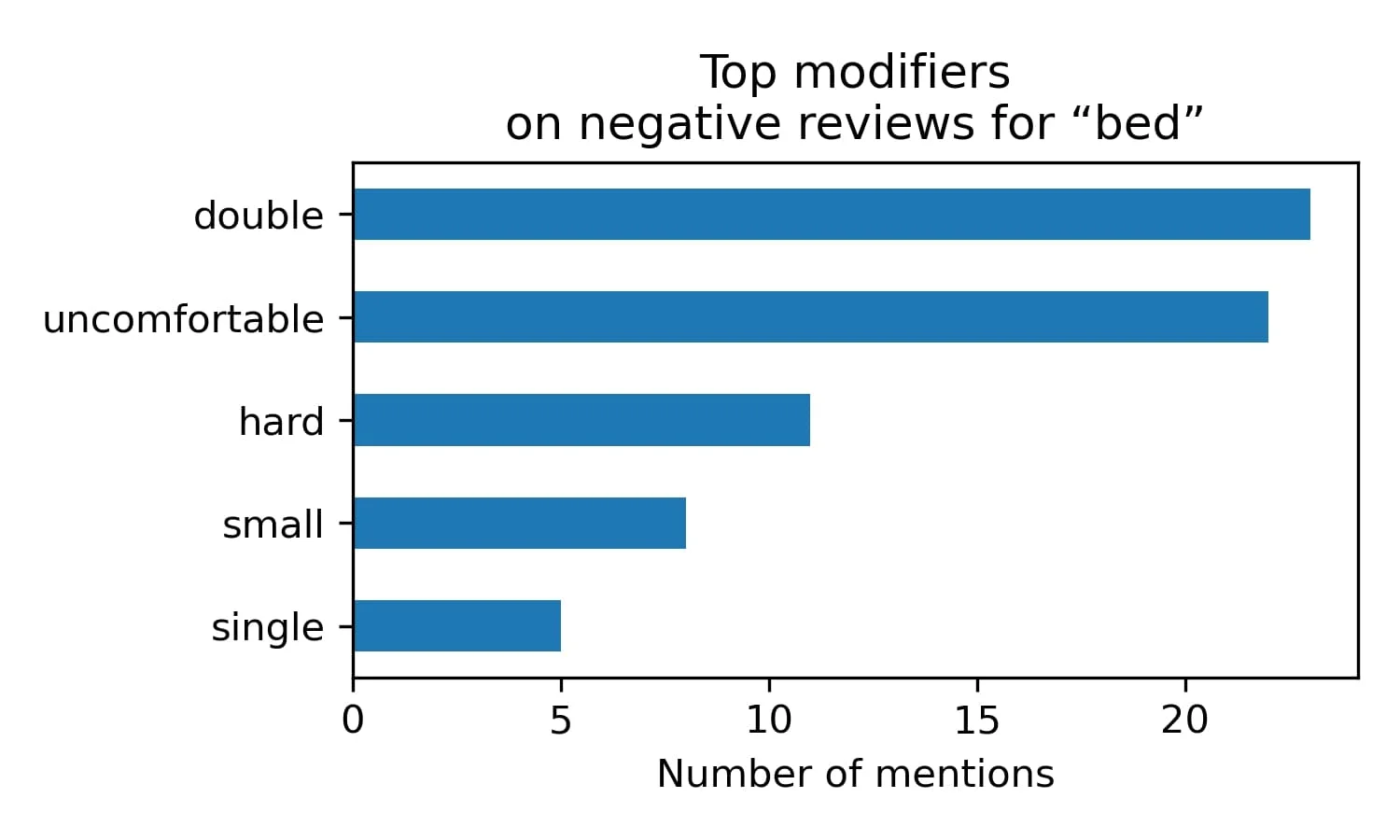
Utöver det är ett annat stort problem som kunderna rapporterat om värme-, ventilations- och luftkonditioneringssystemet på plats på hotellet - ”varmt” och ”kallt” var de största bekymmerna från kunderna när det gäller deras rum. En särskild smärtpunkt var rumsfönstret, som så ofta nämndes för att identifieras som ett av våra nyckelord, särskilt eftersom det krävde personalhjälp för att öppna vissa rums fönster.

I den meningen, personalen växte ofta upp i positiva och negativa recensioner, med vissa kunder som ansåg dem oförskämda. Men oftare ansågs de vara vänliga och hjälpsamma, även om en särskild intressepunkt är att många kunder tyckte att hotellet var underbemannat. Slutligen förblir omnämnandet av personalen i recensioner relativt konstant över tiden.
Hotellets läge var en annan framträdande faktor i positiva recensioner. Det uppfattades övervägande som en positiv aspekt, med många allmänna komplimanger, och ansågs bekvämt och centralt beläget. En avgörande trend som företaget bör vara medveten om är dock att platsen över tid har nämnts mindre ofta i positiva recensioner medan det i allt högre grad hänvisas till i negativa recensioner. Även om detta kan relatera till den externa platsen och därför till externa faktorer utanför omedelbar hotellkontroll, är det en potentiell trend värt att hålla ett öga på.
Slutligen är det värt att nämna att ett betydande antal negativa recensioner kommenterade hotellets Wi-Fi, främst på grund av att det betalades och inte gratis.
Affärsintelligens och sentimentanalysprojekt som detta kan ge värde till många användningsfall.
Numera sker en betydande del av shoppingen online. E-handel representerar en växande trend med nästan obegränsad tillgång till resurser, marknader och produkter i realtid var som helst på planeten. Att förstå marknadsföringens räckvidd när det gäller kundsegmentering är mycket viktigt för ett företag att anpassa ansträngningarna för att nå önskad målgrupp.
Nästan varje e-handelsplattform innehåller ett recensionsavsnitt där kunder kan kommentera de produkter de köpte. Det här kommentaravsnittet representerar en värdefull datakälla som kan ge värde till verksamheten.
Genom NLP-tekniker är det möjligt att få insikter om vad kunden gillar eller ogillar med produkterna. Dessa insikter kan hjälpa till att förstå brister eller ytterligare förbättringar av produkten och/eller plattformen. Vi kan identifiera viktiga aspekter som ger kunden osäkerhet eller andra känslor, så att vi kan agera på dem.
Det blir också möjligt att se utvecklingen av användarens sentiment på produkten över tid och mäta hur förändringar påverkade kundernas övergripande åsikt.
Gästfrihetsbranschen är en mycket konkurrenskraftig sektor där små detaljer kan visa sig vara väsentliga fördelar jämfört med konkurrenter.
Booking, Trivago, Google och andra plattformar listar ofta anläggningar. Den gemensamma aspekten mellan dessa plattformar är att kunder ofta använder dem för att lämna recensioner. Genom att analysera recensionspoäng och kommentarer är det möjligt att samla in insikter om kundernas åsikter om viktiga aspekter av verksamheten.
Dessa data gör det möjligt för oss att tolka vilka aspekter av verksamheten som behöver ändras eller uppmärksammas, vilka delar kunder värderar och eventuellt förutse några justeringar vi bör överväga.
Restauranger, kaféer och barer förlitar sig alltmer på deras online-närvaro för att locka kunder. Detta innebär att listas på flera plattformar som Yelp, Google, Zomato och Tripadvisor, som gör det möjligt för användare att lämna betyg och skriftliga recensioner. Ofta väljer kunder vilka nya platser de ska prova enbart baserat på dessa recensioner, vilket gör dem till en nyckel till att förstå hur verksamheten presterar.
Det ligger i dessa företags bästa intresse att använda all denna feedback för att hitta sätt att få en fördel över sina konkurrenter. Att analysera möjliga kundsmärtpunkter hjälper till att investera i värdefulla förbättringar, och att spåra konsumenternas känslor över tid säkerställer att investeringarna lönar sig.
Varje anläggning som växer utöver en viss storlek måste förlita sig på Data Science-tekniker för att analysera många recensioner de kan få på olika plattformar. Denna process kan automatiseras, vilket ger snabb feedback och en bred vision om vad som lockar eller besvärar kunder. Detta kommer att hjälpa chefer att ta sina mattjänster till nästa nivå.
Underhållningsindustrin är bred, inklusive allt från filmer, TV-program, och Youtube-kanaler till nöjesparker och cirkusakter. Gemensamt för alla dessa företag, särskilt i den digitala tidsåldern, är att de är föremål för recensioner och kommentarer, både från kritiker och åskådare.
När verksamheten växer kan antalet recensioner bli ohanterliga, vilket gör det svårt att förstå befolkningens övergripande känsla. Det är här NLP-tekniker bör spela in, så att många kommentarer kan analyseras och analyseras för att extrahera värdefulla och handlingsbara insikter.
Sammanfattningsvis analyserade vi kundernas feedback om deras vistelse på ett hotell med hjälp av Natural Language Processing -tekniker och avslöjade handlingsbara insikter som direkt kan påverka affärsbeslutsfattandet. Denna analys och de underliggande processerna kan användas för många andra applikationer, vilket ger värde till företag inom många sektorer.
Detta projekt slutfördes på 3 dagar med ett team av 2 Imaginary Cloud Data Scientists. Imaginary Cloud tillhandahåller datavetenskap och AI-utvecklingstjänster, med fokus på att ge högsta värde till sina kunder genom skräddarsydda lösningar och en smidig process.
Kontakta oss om du behöver en anpassad Data Science eller AI-lösning:


Alexandra Mendes är Senior Growth Specialist på Imaginary Cloud med 3+ års erfarenhet av att skriva om mjukvaruutveckling, AI och digital transformation. Efter att ha avslutat en frontend-utvecklingskurs tog Alexandra upp några praktiska kodningskunskaper och arbetar nu nära med tekniska team. Alexandra brinner för hur ny teknik formar affärer och samhälle och tycker om att förvandla komplexa ämnen till tydligt och användbart innehåll för beslutsfattare.

Datavetare brinner för datavetenskap och vakar över dess etiska konsekvenser. Förutom arbete älskar jag att nörda på musik och läsa en bra historia.

Data Scientist som älskar att utforska problem. På min fritid undervisar jag basket till barn och tycker om att gå till stranden.
People who read this post, also found these interesting:





.webp)
.webp)
