

Der er mange Relational Database Management Systems (RDBMS) tilgængelige på markedet, og PostgreSQL og MySQL er blandt de to mest populære. Begge muligheder giver mange fordele og er meget konkurrencedygtige. Derfor er det vigtigt at forstå deres forskelle for at vælge den mest passende til hvert enkelt tilfælde.
I den forstand giver denne artikel en dyb sammenligning mellem PostgreSQL og MySQL under hensyntagen til aspekter som datatyper, ACID-overholdelse, indekser, replikering og mere. Endvidere indebærer det, hvilken man skal vælge, og fremhæver vigtigheden af at overveje ansøgningens krav.
PostgreSQL blev først frigivet i 1996 og oprettet i University of California, ved Computer Science Department. I øjeblikket er dens udvikling under PostgreSQL Global Development Group.
PostgreSQL er et open source relationsdatabasestyringssystem (RDBMS), der også kan betragtes som et objekt-relationelt databasestyringssystem (ORDBMS) da det understøtter nogle objektorienterede funktioner, såsom tabelarv og funktionsoverbelastning.
MySQL blev introduceret på markedet i 1995, kort før PostgreSQL. Det er et open source (tilgængeligt under GNU GLP) Relational Database Management System (RDBMS). Desuden administreres og ejes denne database af Oracle Corporation.
I årenes løb har MySQL opbygget et ganske imponerende og pålideligt ry. Plus, det skiller sig også ud i samfundet for sin brugervenlighed.
Før vi går videre til sammenligningen mellem PostgreSQL vs MySQL, lad os først forstå, hvordan ORDBMS adskiller sig fra RDBMS. MySQL er en rent relationel database. Derfor gemmes dataene i et struktureret format (med kolonner og rækker). Desuden kan værdierne i hver tabel relateres til hinanden, og tabeller kan endda relatere til andre tabeller.
PostgreSQL er en ORDBMS. Disse systemer består af en relationel model, hvilket betyder, at det stadig er muligt at relatere værdier og tabeller, samtidig med at man følger den objektorienterede models principper. Således kan ORDBMS omfatte begrebet klasser, objekter og arv.
Med hensyn til struktur er MySQL og PostgreSQL faktisk ret ens. De bruger begge tabeller som deres kernekomponent, hvilket betyder, at dataene er organiseret i rækker og kolonner. Derudover integrerer PostgreSQL også lagrede procedurer, visninger, begrænsninger, triggere, roller og yderligere understøttelser NoSQL. Til gengæld tilbyder MySQL næsten de samme funktioner (eller meget identiske), og siden MySQL 5.7-versionsudgivelsen (2015) begyndte den også at inkludere NoSQL-funktioner.
Både PostgreSQL og MySQL er blandt mest populære databaser tilgængelig på markedet. For at være mere præcis, ifølge popularitetsstatistikker fra maj 2021, er MySQL stadig mere populær end PostgreSQL, da Højdepunkter i DB-Engines Ranking.
Desuden er disse data tilpasset TOPDB Topdatabaseindeks, som er baseret på Googles søgeresultater. Ifølge indekset er MySQL i anden position og PostgreSQL i den sjette.
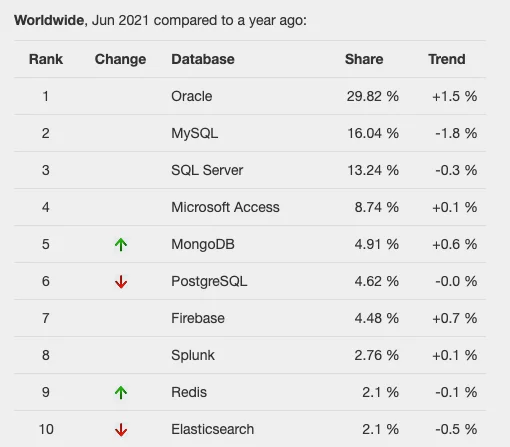
Med hensyn til community-support drager både PostgreSQL og MySQL fordel af aktive fællesskaber såvel som omfattende dokumentation støtte.
I øjeblikket gør både PostgreSQL og MySQL udviklere i stand til at arbejde med JSON som en datatype i tabeller. Imidlertid, tingene var ikke altid sådan. Indtil lanceringen af MySQL 5.7.8-versionen understøttede databasesystemet ikke JSON-filer.
Indtil videre JSON-understøttelse forbliver en af de førende NoSQL-funktioner, som MySQL har integreret. I modsætning hertil understøtter PostgreSQL yderligere XML, opbud, brugerdefineret type, og hstore, hvilket giver mulighed for at operere med flere datatyper end MySQL. Den største fordel ved at have en række muligheder til rådighed er, at Det kan øge funktionaliteten. For eksempel, ved at acceptere arrays som en datatype, kan PostgreSQL også tilbyde værtsfunktioner, der er kompatible med disse arrays.
Ikke desto mindre kan det på trods af fordelene ved at bruge alternative formater til lagring af data også være mere komplekst at implementere sådanne dataformater, da de ikke følger en veletableret standard. Derfor er komponenter, der bruges sammen med databasen, muligvis ikke i overensstemmelse med PostgreSQL-formater. Dette behøver ikke at være en ulempe, men snarere noget at passe på.
Når det kommer til kodning i PostgreSQL mod MySQL, et par forskelle bør overvejes. Lad os starte med at skelne mellem store og små bogstaver. På den ene side PostgreSQL skelner mellem store og små bogstaver. Dette betyder, at udviklere skal bruge store bogstaver i strenge, som de vises i databasen; ellers mislykkes forespørgslen. På den anden side skelner MySQL ikke mellem store og små bogstaver. Derfor er der ikke behov for at kapitalisere strenge, mens du spørger.
En anden forskel med hensyn til kodning ligger i tegnenes sæt og strenge. PostgreSQL tillader ikke UTF-8 syntaks; Således er der ikke behov for at konvertere sæt og strenge til denne syntaks. I modsætning hertil kræver nogle versioner af MySQL denne konvertering.
SQL står for Structured Query Language, og det betragtes som standarden, når det kommer til forespørgsel på datasprog. Det anvendes dog ikke nødvendigvis på samme måde på tværs af alle databasesystemer.
SQL's grundlæggende elementer er SELECT, INSERT, DELETE og UPDATE. Derudover kan det også involvere nogle ekstra funktioner og forskelle med hensyn til syntaks.
MySQL er kun delvist SQL-kompatibel fordi det ikke understøtter alle funktionerne (f.eks. Ingen kontrolbegrænsning). Det giver dog mange udvidelser. Til gengæld PostgreSQL er mere SQL-kompatibel end MySQL, i overensstemmelse med de fleste af de vigtigste funktioner. For at være mere præcis understøtter PostgreSQL i det mindste 160 ud af de 179 obligatoriske funktioner.
Jo mere omfattende en database er, jo mere afgørende bliver indekser. Når du håndterer tabeller med millioner af rækker, kan indekser være yderst nyttige og kan forbedre databasens ydeevne. Før vi ser på de særlige forhold i hvert databasesystem, lad os først angive, hvad de har til fælles: PostgreSQL og MySQL tilbyder support til B-træer og hashindekser. Nu hvor det er klart, lad os tage et dybt kig på deres tilgange til indekser.
På den ene side gemmes de fleste indekser (PRIMARY KEY, UNIQUE, INDEX og FULLTEXT) i MySQL i B-træer. Der er dog nogle undtagelser:
På den anden side overvejes indekserne i PostgreSQL Sekundære indekser. Derfor gemmes indekserne adskilt fra tabellens bunke, som er det vigtigste dataområde. Når der udføres en indeksscanning, skal dataene derfor hentes fra både bunken og indekset. For at løse denne ulempe udviklede PostgreSQL support til Indeksscanninger, hvilket betyder, at udviklere ikke længere behøver at bede om heap-adgang for at forespørge et indeks. To mål skal følges for at anvende denne metode: indekstypen skal understøtte indeks-scanninger, og forespørgslen kan kun referere til kolonner, der er gemt i indekset.
For at få mest muligt ud af scanningsmetoden med kun indeks kan udviklere oprette en dækningsindeks. Dækningsindekset henter alle nødvendige kolonner. Således inkluderer det de kolonner, der kræves af en bestemt type forespørgsel, der kører ofte.
Dækkende indekser blev kun tilgængelige i PostgreSQL siden version 9.2 (2012). På det tidspunkt brugte MySQL dem imidlertid allerede til at hente data ved at scanne indekset uden at skulle røre ved tabeldataene. Sidst men ikke mindst understøtter PostgreSQL-indekser yderligere funktioner, som MySQL endnu ikke har udviklet, såsom delvise indekser, ekspressionsindekser og bitmapindekser.
ACID står for atomicitet, konsistens, isolation og holdbarhed. Den beskriver de egenskaber, som et robust databasesystem skal have for at sikre Transaktionerne er pålidelige og konsekvente. Som vi forklarer i vores SQL mod NoSQL artikel, mange (for ikke at sige de fleste) relationelle databasestyringssystemer er ACID-kompatible. Dette betyder ikke, at NoSQL-databaser ikke kan være ACID-kompatible. Faktisk, MongoDB, Apache's CouchDB og IBM Db2 fungerer som et eksempel på NoSQL-databasesystemer, der kan integrere og følge ACID-principper.
MySQL er det ikke, da det ikke understøtter nogle principper, såsom konsistens, isolation og holdbarhed. MySQL inkorporerer dog komponenter som InnoDB og NDB Cluster storagemotorer, så udviklere kan følge ACID-modellen nøje, hvis de ønsker det.
Til sammenligning PostgreSQL er syre-kompatibel da det giver alle de nødvendige funktioner til at vedtage ACID-modellen fuldt ud. Ikke desto mindre kan implementering af disse funktioner og følge de respektive egenskaber bremse ydeevnen.
Som nævnt står „jeg“ i ACID for „isolation“, hvilket ikke er særlig let at opnå. For virkelig korrekt isolering skal udviklere sikre, at transaktioner er serialiserbar, hvilket betyder, at resultatet af gennemførelsen af en række transaktioner bør være det samme som en vis seriel udførelse af disse transaktioner. Således tilbyder en database med serialiserbarhed vilkårlige læse/skrivetransaktioner og er derfor i stand til at garantere konsistens. Selvom ACID-egenskaber sikrer pålidelighed og konsistens (et plus for PostgreSQL), kan fuldstændig isolering desværre også begrænse simultan og generelt langsommere ydelse (PostgreSQLs ulempe).
PostgreSQL introducerede multi-version samtidighedskontrol (MVCC) funktioner først end MySQL, og dette plejede at være en af dens mest betydningsfulde fordele.
MVCC funktioner giver udviklere samtidig adgang til databasen uden at skulle låse dataene. Derfor ser hver udvikler, der er forbundet til databasen, et „øjebliksbillede“ af dataene, mens de spørger dataene. Indtil en transaktion er fuldt udført, kan de andre brugere/udviklere ikke se ændringerne i databasen. Kort sagt, læsere og forfattere blokerer ikke hinanden, og MVCC gør det lettere for dem at interagere. Denne funktion giver“transaktionsisolering„(eller“snapshot-isolering„, som Oracle navngiver det) gennem hver databasesession, og undgår dermed transaktioner, der virker inkonsekvente og mulige konflikter med låse.
I MySQL er det muligt at drage fordel af MVCC funktion ved hjælp af InnoDB. InnoDB er standard MySQL-motoren, der gør det muligt for databasesystemet at være ACID-kompatibelt og have MVCC. Udviklere kan vælge at bruge andre motorer; det kan dog betyde at miste disse to egenskaber.
Som navnet antyder, består replikering af en proces, der giver udviklere mulighed for at kopiere data fra en database til replika-databaser, hvilket gør det muligt for hver bruger at have det samme niveau af information. Plus, replikering medfører flere fordele, såsom automatiske sikkerhedskopier, fejltolerance, skalerbarhed, og evnen til at udføre lange forespørgsler uden at forstyrre hovedklyngen.
Begge dele PostgreSQL og MySQL understøtter replikering. I MySQL er replikering envejs asynkron; således fungerer en databaseserver som den primære, og de andre er „slaver“ (replikaerne). I modsætning hertil tilbyder PostgreSQL synkron replikering, hvilket betyder, at den har to databaser, der kører samtidigt, og den primære database er synkroniseret med replikadatabasen. Yderligere, kaskade og synkron replikering kan også udføres, når du bruger PostgreSQL.
Et andet aspekt, som begge PostgreSQL- og MySQL-understøttelse er klyngedannelse. Clustering bruger delt lagring til at replikere et lige sæt data til hver node i et miljø. Dette gør det muligt for databaser at tolerere fejl, på grund af redundansen skabt ved at replikere data på tværs af flere noder i et miljø.
På trods af at have envejs asynkron replikation, MySQL-klynge vedtager synkron replikering internt. På denne måde fjerner MySQL enkelte fejlpunkter fra systemet og sikrer, at dataene skrives til forskellige noder, hvilket undgår enhver negativ indvirkning og fejl på transaktionerne. Plus, MySQL-udviklere kan også bruge MySQL Cluster, en multimaster-teknologi, der prioriterer lineær skalering.
Med hensyn til klyngedannelse understøtter PostgreSQL streaming eller synkrone replikationer og har også Postgres-XL, som er et databaseklyngemiljø.
Med hensyn til de forskelle, der er diskuteret indtil videre, er valget mellem begge databasesystemer ikke altid så klart. En ting, vi ved, kan sige med sikkerhed, er, at uanset hvad, der ikke er et forkert svar. Begge databasesystemer er populære og har et pålideligt omdømme. Den ene kan dog være mere egnet end den anden, afhængigt af konteksten.
Som nævnt er MySQL en RDBMS, hvorimod PostgreSQL er en ORDBMS, da den inkluderer objektorienterede funktioner, såsom funktionsoverbelastning og tabelarv. Denne forskel i sig selv kan være nok til, at nogle udviklere vælger PostgreSQL, i betragtning af at det gør det lettere for udviklere at modellere komplekse applikationsobjektstrukturer.
Desuden PostgreSQL er mere SQL-kompatibel end konkurrentalternativet og er også kendt for at opretholde dataintegritet ved transaktioner, ved at vedtage ACID-modellen. Tværtimod kræver MySQL brug af InnoDB og NDB Cluster lagringsmotorer for at være ACID-kompatibel. Men ikke at skulle være ACID-kompatibel kan nødvendigvis også gøre MySQL hurtigere når det kommer til læsning af data.
Faktisk har valg af MySQL også sine fordele. Indtil videre er det stadig mere populært end PostgreSQL og drager fordel af en omfattende fællesskab såvel som et stort antal tredjepartsværktøjer. Et andet stort plus er, at MySQL skiller sig ud for at være hurtig, pålidelig og en ukompliceret database system, der er let at forstå og sætte op. Desuden har MySQL i de seneste år fortsat introduceret relevante funktioner (såsom MVCC).
Alt i alt er PostgreSQL rigere med hensyn til indbyggede funktioner, og det har bevist sin evne til at håndtere komplekse forespørgsler (f.eks. Underforespørgsler, filtrerede resultater, jointer osv.), samt omfattende databaser. Men hvis prioriteten er at have et databasesystem, der er hurtigt, pålideligt og ret nemt at administrere, så er MySQL også et glimrende valg.
I sidste ende, valget mellem PostgreSQL vs MySQL vil altid afhænge af ansøgningens krav. For eksempel, når du håndterer en database med en masse ustrukturerede data, kan det være mere fordelagtigt at vælge PostgreSQL, da det understøtter flere datatyper.
Sammenligningen mellem PostgreSQL vs MySQL bør ikke fokusere på, hvilken der er bedre, men snarere på at vælge den ene eller den anden til en bestemt applikation. Med andre ord, ansøgningskrav skal altid tilpasses databasesystemets egenskaber og evner.
For at vælge klogt er det derfor afgørende at forstå, hvordan PostgreSQL og MySQL adskiller sig med hensyn til kritiske aspekter, og hvordan udviklere kan få mest muligt ud af hver mulighed.

Marketing praktikant med særlig interesse for teknologi og forskning. I min fritid spiller jeg volleyball og forkæler min hund så meget som muligt.

Softwareudvikler, der elsker backend-siden, smidig og RoR-afhængig. En fan af fodbold og en entusiast af cykling. Lad os ride!
People who read this post, also found these interesting:







.webp)