

Der er mange databaser tilgængelige på markedet, og det kan være ekstremt svært at vide, hvilken man skal vælge. En glimrende måde at begynde at udelukke nogle muligheder på er først at have en klar forståelse af vigtigste forskelle mellem SQL- og NoSQL-databaser.
I denne artikel præsenterer vi en detaljeret sammenligning mellem disse to forskellige typer databaser med hensyn til struktur, skema, skalerbarhed, forespørgsel og transaktioner.
Desuden forklarer vi hvornår skal du bruge SQL eller NoSQL databaser og giver yderligere en historisk kontekst for dem, der er interesseret i at vide, hvordan denne dikotomi startede.
SQL er et programmeringssprog; det er dog ikke et generelt programmeringssprog som Java, Javascript, eller Python. I stedet følger SQL et specifikt formål: at få adgang til og manipulere data.
For at være mere præcis står SQL for Struktureret forespørgselssprog. Det er et forespørgselssprog, der gør det muligt at hente specifikke data fra databaser, og i den forstand er det designet til at få adgang til, gemme og manipulere relationelle databaser.
En relationsdatabase er en type database (normalt organiseret i tabeller), der muliggør genkendelse og adgang til data i forhold til et andet stykke data inden for den samme database. Med andre ord gemmer den relaterede data på tværs af flere tabeller, som er organiseret i kolonner og rækker, og giver brugeren mulighed for at forespørge data (eller information) fra forskellige tabeller samtidigt.
En relationsdatabase er en database, der følger relationel model af data. For at vedligeholde en relationsdatabase skal en Relationsdatabasestyringssystem (RDBMS) bruges. For at operere på dette system har mange databaser derfor en tendens til at bruge SQL til at administrere og forespørge databasen. Således SQL er et sprog, der giver mulighed for kommunikation med data i et RDBMS.
Et vigtigt aspekt at rydde ud er, at SQL ikke er et databasesystem i sig selv. Sandheden skal siges, når sammenligning af SQL vs NoSQLDe væsentligste forskelle, der vurderes, er relationelle databaser vs ikke-relationelle databaser (samt distribuerede databaser).
Et andet aspekt at overveje er, at SQL ikke er det eneste programmeringssprog, der er i stand til at forespørge relationelle databaser, men det er bestemt det mest populære. Derfor bruges udtrykkene „SQL-databaser“ og „relationelle databaser“ ofte om hverandre. MySQL, PostgreSQL, Microsoft SQL Server og Oracle-database er blandt de mest kendte RDBMS, der bruger SQL.
NoSQL refererer til ikke-relationelle databaser og til distribuerede databaser. NoSQL kan også stå for „Ikke kun SQL“ for at fremhæve, at nogle NoSQL-systemer muligvis også understøtter SQL-forespørgselssprog. Faktisk, før du går videre, er det vigtigt at huske på, at NoSQL ikke nødvendigvis betyder, at en database ikke understøtter SQL. I stedet, det betyder, at databasen ikke er en RDBMS.
Mens traditionelle RDBMS er afhængige af SQL-syntaks til at gemme og forespørge data, på den anden side, NoSQL databasesystemer bruge andre teknologier og programmeringssprog til at lagre strukturerede, ustrukturerede eller semistrukturerede data.
Den relationel model af data blev introduceret i 1970 af E.F. Codd. Fire år senere (1974) introducerede Raymond Boyce og Donald Chamberlin SQL, som oprindeligt blev udviklet til forespørgsler IBM's System R, et databasestyringssystem.
Det tog ikke lang tid, før SQL blev en massiv succes blandt relationelle databasesystemer på grund af dets utrolige anvendelighed og evne til at reducere dataduplikering. Således blev det snart og i lang tid betragtet som det dominerende sprog i relationelle databasesystemer. Men så skete der en lille ting: World Wide Web, i 1989.
Konsekvenserne? Flere data. Masser af flere data. Som vi ved, var Internettets vækst ikke langsom, og da nye kilder og datamængder fortsatte med at forstyrre vores verden, begyndte relationelle databaser at kæmpe.
I begyndelsen af det 21. århundrede, for at håndtere denne enorme mængde data, ikke-relationelle systemer, såsom Storbord (af Google, i 2006) og Dynamo (af Amazon, i 2007), begyndte at lave deres egen måde. Fokus var på skalerbarhed og hurtig anvendelse.
I løbet af disse år, og efterhånden som flere ikke-relationelle databaser begyndte at dukke op, blev begrebet NoSQL blev meget populær (selvom udtrykket først blev opfundet i 1998 af Carlo Strozzi, og ikke-relationelle databaser eksisterer siden 60'erne).
Repræsenterede begyndelsen af århundredet Slutningen af SQL og følgelig af relationelle databaser? - Nej, selvfølgelig ikke. Af to grunde:
Tiden har lært os, at SQL-databaser ikke er bedre eller værre end NoSQL-databaser. De foretrækkes simpelthen og er mere egnede til forskellige applikationer vedrørende databasestyringssystemer (DBMS).
Ifølge 2021 DZone Data Persistence Trend Rapport (billede nedenfor), relationelle databaser er de mest populære DBMS. NoSQL-databaser henviser imidlertid til alle ikke-relationelle DBMS'er (inklusive graf, dokumentorienteret, nøgleværdi, kolonneorienteret og andre). Derfor kombineret, NoSQL-databaser er i øjeblikket mere populære end relationelle databaser.
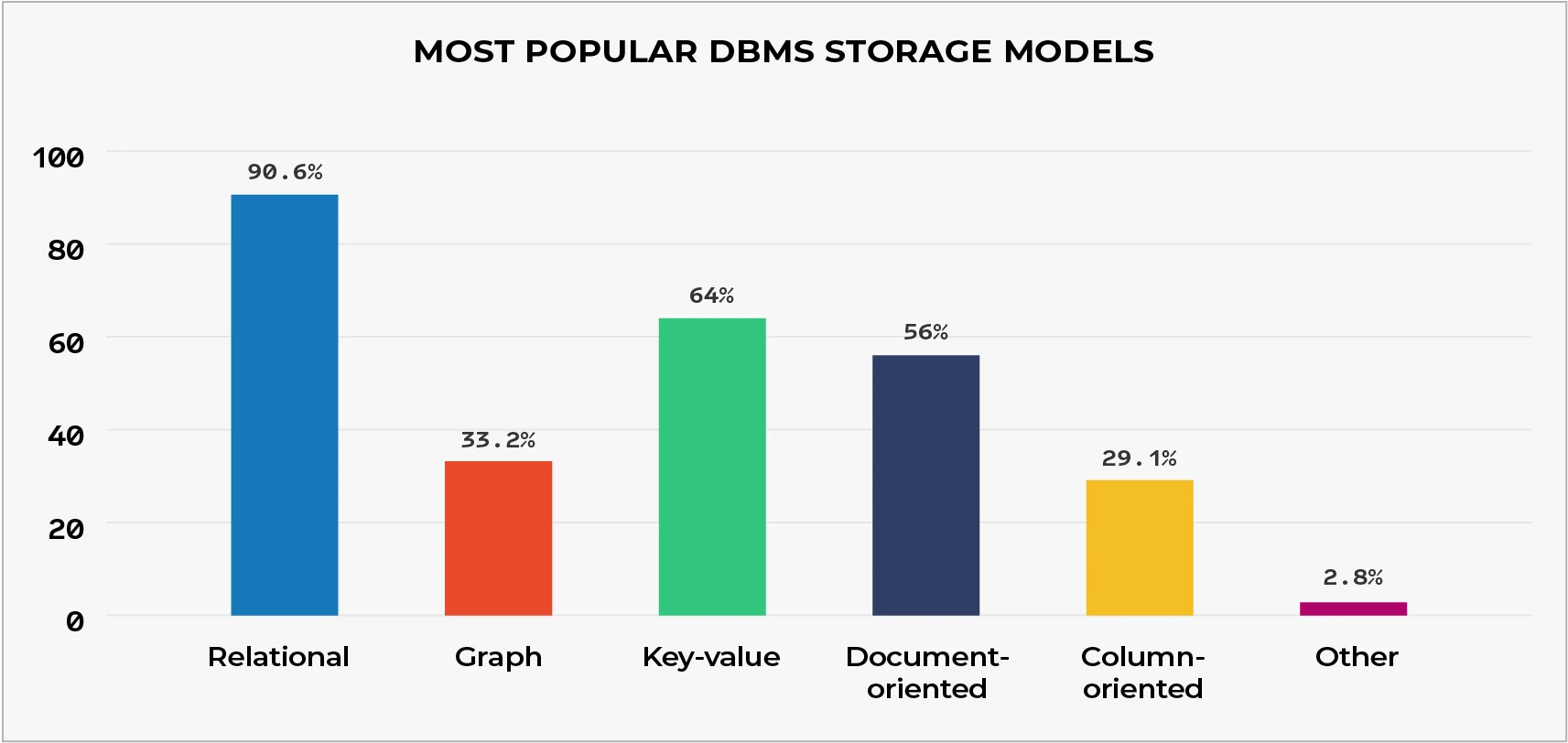
Kort sagt, det rigtige valg, når det kommer til SQL mod NoSQL afhænger først og fremmest af at kende den type database, der passer bedre til hver virksomheds eller organisations formål. Før vi går videre til, hvornår vi skal bruge hver, lad os først se på deres forskelle.
SQL-databaser organiserer og gemmer data efter tabeller med faste kolonner og rækker. Tværtimod kan NoSQL-databaser gemmes på forskellige måder:
SQL-databaser kræver en fast foruddefineret skema, og alle data skal følge en lignende struktur. Derfor kræves der en masse forberedelse med hensyn til systemet på forhånd. Desuden er fleksibiliteten kompromitteret, i betragtning af at potentielle ændringer i strukturen kan være komplekse, meget komplicerede og kan forstyrre systemet.
Til gengæld følger NoSQL-databaser en dynamisk skema for ustrukturerede data. Da det ikke kræver en foruddefineret struktur, er ændringer lettere at udføre. Derfor har NoSQL-databaser større fleksibilitet; fleksibilitet kan dog også kompromittere pålideligheden på trods af fordelene.
Med hensyn til skalerbarhed, SQL-databaser følger en lodret tilgang, også kendt som „scale-up“. I databaser betyder det, at det er muligt at øge mængden af data i en enkelt server ved at tilføje mere strøm til en eksisterende maskine ved at bruge for eksempel en CPU, RAM eller SSD.
På den anden side NoSQL-databaser skaleres vandret (også kendt som „scale-out“), da de skaleres på tværs af råvareservere, hvilket betyder, at flere servere føjes til puljen af ressourcer, og data kan distribueres på tværs af disse ressourcer.
JOIN-operationer gør det muligt at forbinde og relatere stykker data. Generelt er NoSQL-databaser (kan men) ikke designet til at understøtte JOIN effektivt. Objekter kan være på forskellige servere i ikke-relationelle databasesystemer uden at være bekymret for sammenføjning af tabeller fra flere servere.
NoSQL giver således mulighed for nem skalering ved at dele data og have et routinglag, der kan omdirigere forespørgslen til det relevante skår, hvilket gør NoSQL-databaserne meget skalerbare og hurtige at forespørge. Det kompromitterer imidlertid dataintegriteten og følger ikke en ACID-tilgang.
„Skalering ud“ i RDBMS er generelt vanskeligere at implementere på grund af ACID-koncepterne relationelle databaser følger. For at en multi-server RDBMS kan opretholde dataintegritet på tværs af transaktioner, ville det kræve en hurtig backend-kommunikationskanal. Denne kanal skulle synkronisere alle skrivninger og transaktioner samt forhindre mulige dødvande.
Selvom det er teknisk muligt at skalere ud i RDBMS, skaleres disse databasesystemer typisk op for at sikre dataintegritet og ACID-principper i stedet for at distribuere data på tværs af flere servere.
Som tidligere nævnt har SQL eksisteret i lang tid; det er således bredt beundret som et modent og populært sprog, der drager fordel af et pålideligt omdømme. Det er utroligt effektivt, når det kommer til forespørgsler om data, manipulering og hentning af data fra relationelle databaser. Plus, det skiller sig også ud for at være deklarativt og let.
En anden stor SQL-fordel er, at det er relativt let at lære, hvilket betyder, at marketingfolk og forretningsanalytikere kan bruge det uden nødvendigvis at kræve teknisk medarbejders hjælp.
Når det kommer til kører NoSQL-forespørgsler, det er måske ikke så ligetil som SQL-databaser, da det normalt har brug for at udføre ekstra databehandling og ikke har et deklarativt forespørgselssprog. Derfor udføres disse opgaver normalt af dataforskere eller udviklere.
Alt i alt hvordan man kører forespørgsler i NoSQL-databaser Det afhænger meget af den pågældende database. For eksempel i MongoDB, for at anmode om data fra JSON-dokumentdatabasen, er det nødvendigt at specificere dokumenterne med de egenskaber, som resultaterne skal matche, og anvende følgende funktion: db.collection.find (). Andre populære løsninger kan omfatte oprettelse af forespørgselsfunktionaliteten direkte i applikationslaget (og ikke i databaselaget) eller implementering MapReduce.
SQL-databaser følger typisk ACID egenskaber med hensyn til transaktioner. ACID står for Atomic, Consistent, Isolated og Durable. Lad os se nærmere på for at forstå mere præcist, hvad det betyder:
Som man kan se, ACID-modellen sikrer, at en transaktion er pålidelig og konsekvent. Derfor er databaser, der følger denne model, bedst egnet til organisationer og virksomheder, der ikke kan risikere ugyldige og afbrudte datatransaktioner eller andre fejl (f.eks. finansielle institutioner).
Relationelle databasestyringssystemer (såsom MySQL, SQLite, PostgreSQL osv.) er ACID-kompatible. Selvom NoSQL-database-tilgangen normalt strider mod ACID-principper, kan nogle NoSQL-databaser (f.eks. MongoDB, IBM's Db2 og Apache's CouchDB) også integrere og følge ACID-regler.
I ikke-relationelle databaser er datapålideligheden og konsistensen af at være ACID-kompatibel normalt ikke en førsteprioritet, i betragtning af at det kan kompromittere hastighed og høj tilgængelighed.
For NoSQL-databaser har prioriteten en tendens til at fokusere på fleksibilitet og på en høj transaktionsrate. Af denne grund er BASE-model følges i mange NoSQL-databasesystemer. Det står for Grundlæggende tilgængelig, blød tilstand og til sidst konsistent.
NoSQL-databaser følger normalt BASE-modellen, som giver mere elasticitet end ACID-modellen. Som nævnt er ACID bedre for virksomheder og organisationer, der har brug for at sikre hver transaktions konsistens, forudsigelighed og pålidelighed.
Tværtimod er BASE-modellen mere velegnet til virksomheder, der prioriterer høj tilgængelighed, skalerbarhed og fleksibilitet i datatransaktioner. For eksempel håndterer en social netværksapp enorme mængder data, der ofte ikke er særlig godt struktureret; i så fald kan en BASE-model gøre det lettere (og hurtigere) at gemme data.
Nu hvor vi har dækket vigtigste forskelle mellem SQL og NoSQL, det er tid til at forklare, hvornår man skal bruge det ene eller det andet. Før du træffer en endelig beslutning, er det vigtigt at overveje følgende aspekter:
Med hensyn til det første aspekt er SQL-databaser en mere passende mulighed end NoSQL, når data integritet og konsistens Det er nøglen i en organisation.
Der er ofte den misforståelse, at relationelle databaser ikke er en god mulighed for at håndtere store mængder data. Det er ikke ligefrem sandt. Mange SQL-databaser, såsom PostgreSQL og MySQL, kan faktisk håndtere meget respektfulde mængder data.
Men da RDBMS'er, der bruger SQL, har et fast skema og kræver, at dataene er struktureret, vil det sandsynligvis blive meget udfordrende at holde trit med den krævede vedligeholdelse, smidighed og ydeevne, som for eksempel en virksomhed, der håndterer Big Data, kan kræve.
Ved første øjekast kan det se ud til, at det at have et fast skema er begrænsende. Nå, igen, det afhænger af formålet. At have en foruddefineret skemadatabase gør også SQL-databaser er den mest hensigtsmæssige løsning til håndtering af lønstyringssystemer eller endda til behandling af flyreservationer. Faktisk er de fleste bankinstitutioner afhængige af et SQL-databasesystem.
Som vi tidligere har forklaret, relationelle databaser er typisk ACID-kompatible, hvilket betyder, at datatransaktioner sikrer integritet, gyldighed og pålidelighed. Plus, SQL begrænser muligvis nogle funktioner, men det er også en meget moden teknologi.
Desuden tilbyder en relationel database og SQL en masse support vedrørende ad hoc-forespørgsler. Denne type databaser er normalt lettere at administrere. Da SQL er et populært forespørgselssprog og relativt let at lære, behøver det ikke nødvendigvis et stort team af ingeniører for at vedligeholde det.
NoSQL-databaser er i stand til gemme forskellige typer data og behøver ikke at være så struktureret som SQL-databaser. Derfor giver ikke-relationelle databaser stor tilpasningsevne og fleksibilitet, hvilket gør det til et mere passende valg, når håndtering af store sæt ustrukturerede og ikke-relaterede data.
Jo mere omfattende datasættet er, jo mere sandsynligt er en NoSQL-database typisk en bedre mulighed. Ikke-relationelle databaser har en tendens til at udmærke sig skalerbarheds- og tilgængelighedskrav, som er ideel til sociale netværk og realtidsapplikationer (f.eks. Onlinespil, onlinemeddelelser), for eksempel.
NoSQL-databaser kræver programmeringskendskab. I modsætning til SQL, som også kan læres af personale fra andre områder såsom ledelse og markedsføring, har NoSQL-databaser normalt brug for nogen med baggrund i kodning og evnen til at tilegne sig andre sprog i henhold til de anvendte databasesystemer.
At vælge den rigtige database er ikke en direkte og præcis beslutning, selv ikke for eksperter. At beslutte, om man skal gå til relationelle eller ikke-relationelle databaser, er en god måde at starte på. Alligevel er det også vigtigt at overveje de mange SQL- og NoSQL-indstillinger tilgængelige på markedet.
For eksempel, for en masse ustrukturerede data, kan CouchDB eller MongoDB være en god mulighed, men måske for høj tilgængelighed, Redis og Cassandra kunne være mere passende. Og disse er alle ikke-relationelle databasesystemer!
På den anden side SQL-databaser giver mange fordele vedrørende datatransaktioner og generel dataintegritet. Desuden kan relationelle databasers relationer let identificeres og defineres, hvilket gør det ligetil at identificere kritisk indsigt.


Marketing praktikant med særlig interesse for teknologi og forskning. I min fritid spiller jeg volleyball og forkæler min hund så meget som muligt.

CEO @ Imaginary Cloud og medforfatter af bogen Product Design Process. Jeg nyder mad, vin og Krav Maga (ikke nødvendigvis i denne rækkefølge).
People who read this post, also found these interesting:





.webp)
.webp)
