
MLops (Machine Learning Operations) er et sæt fremgangsmåder, der gør det muligt for organisationer at implementere, administrere og skalere maskinlæringsmodeller i produktionen. Det forbinder datavidenskab med teknik ved at tilføje automatisering, overvågning og styring på tværs af maskinlæringens livscyklus.
Efterhånden som maskinlæring bevæger sig ind i produktions-AI-systemer, står teams over for udfordringer som modeldrift, upålidelige implementeringer og langsom iteration. MLOps løser disse problemer gennem en veldefineret arkitektur, værktøjer og bedste praksis, der gør maskinlæring pålidelig og vedligeholdelig i stor skala.
MLOPS (maskinlæringsoperationer) er et sæt praksis, der standardiserer og automatiserer udvikling, implementering, overvågning og vedligeholdelse af maskinlæringsmodeller i produktionen. Dens mål er at gøre maskinlæringssystemer pålidelige, skalerbare og gentagelige, på samme måde som DevOps gør for traditionel software, samtidig med at de tager højde for de unikke udfordringer ved data og modeller.
I sin kerne sidder MLOPS i skæringspunktet mellem maskinlæring, softwareteknik og drift. Det dækker hele maskinlæringscyklussen, fra dataindtagelse og modeltræning til implementering, overvågning og kontinuerlig forbedring. I modsætning til traditionel software afhænger maskinlæringssystemer ikke kun af kode, men også af data, funktioner og modelparametre, som alle kan ændre sig over tid og påvirke ydeevnen.
MLOP'er opstod, da organisationer indså, at træning af en model kun er en lille del af at levere værdi med AI. I virkelige miljøer skal modeller versioneres, testes, implementeres sikkert, overvåges for problemer som modeldrift og omskoles, efterhånden som data udvikler sig. Uden MLOP'er kæmper teams ofte med manuelle implementeringer, inkonsekvente resultater og modeller, der nedbrydes lydløst i produktionen.
Store cloud- og forskningsorganisationer definerer MLOP'er i lignende termer:
I praksis giver MLOPS teams mulighed for at skifte fra eksperimentelle bærbare computere til produktions-AI-systemer, der kan stole på, revideres og forbedres over tid - hvilket gør det til en grundlæggende kapacitet for enhver organisation, der seriøst ønsker at bruge maskinlæring i virkelige produkter og tjenester.
MLOP'er er vigtige, fordi mange maskinlæringsinitiativer stopper eller mislykkes ved implementering på grund af fragmenterede arbejdsgange og mangel på operationel disciplin, et problem, der er veldokumenteret i brancheanalyser. En struktureret MLOPS-tilgang tilpasser teams og teknologi, hvilket reducerer produktionstiden og løbende vedligeholdelsesrisiko. Organisationer med klare operationelle rammer ser ofte langt hurtigere adoption og ROI.
Derudover accelererer MLOPS time-to-value for machine learning-initiativer. EN Forbes teknologiråd analysen bemærker, at ML operationelt kaos, såsom langsomme implementeringscyklusser og uklart modelejerskab, forsinker tiden til produktion betydeligt, hvilket styrker behovet for dedikerede operationelle rammer.
Kort sagt er MLops det, der gør produktion AI bæredygtig. Det giver teams mulighed for at bevæge sig hurtigere uden at gå på kompromis med pålideligheden, sikrer, at modeller forbliver nøjagtige over tid, og giver de kontroller, der er nødvendige for at betjene maskinlæringssystemer med tillid i stor skala.
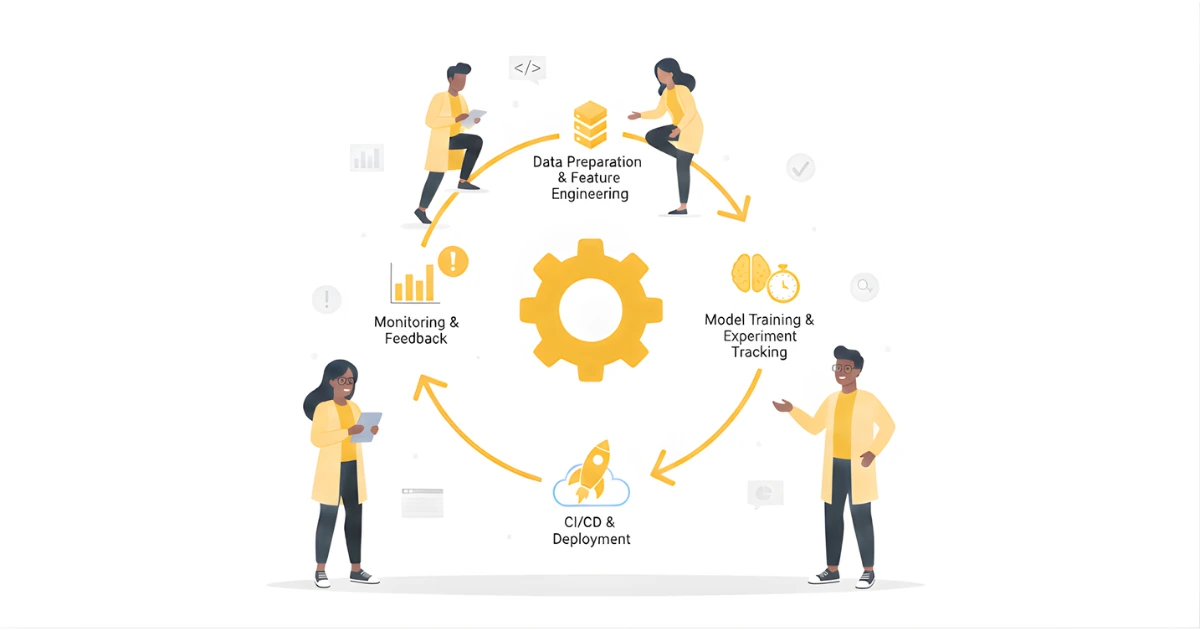
MLops fungerer ved at styre hele maskinindlærings livscyklus, fra dataindsamling til produktionsimplementering og løbende forbedring. Ved at anvende strukturerede processer og automatisering sikrer MLOPS, at modeller er pålidelige, reproducerbare og skalerbare. Livscyklussen kan opsummeres i seks centrale faser:
Maskinlæring begynder med data. MLops pipelines indsamler data fra flere kilder, validerer dem og gemmer dem i et format, der er egnet til træning. Automatiserede pipeliner hjælper med at sikre datakvalitet og konsistens og reducerer fejl, før de påvirker modeller.
Rådata omdannes til funktioner, som modeller kan lære af. MLOps sikrer, at funktionsrørledninger versioneres, reproduceres og overvåges, så de samme transformationer kan anvendes konsekvent i træning og produktion.
Dataforskere træner modeller ved hjælp af forskellige algoritmer og hyperparametre. MLops integrerer eksperimentsporing, modelversionering og automatiseret test for at sammenligne ydeevne og opretholde reproducerbarhed. Værktøjer som MLFlow og Weights & Biases bruges ofte til dette trin.
Før implementering valideres modeller mod usynlige data for at måle nøjagtighed, retfærdighed og pålidelighed. MLops-rørledninger inkluderer automatiserede tests og præstationskontrol for at forhindre regression eller bias i produktionsmodeller.
Modeller implementeres i produktionen ved hjælp af automatiseret CZ/CD rørledninger. Dette sikrer repeterbar, sikker og hurtig implementering på tværs af miljøer. Implementeringsstrategier kan omfatte A/B-test, kanariske udgivelser eller løbende opdateringer for at minimere risikoen.
Efter implementering overvåges modeller for ydeevnedrift, datadrift og fejl. MLops muliggør automatisk omskoling eller advarsler, når målinger nedbrydes. Forvaltningspraksis sikrer overholdelse, logføring og revision af produktions ML-systemer.
Behovet for automatisering og konsistens i operationelle arbejdsgange gentages på tværs af brancheanalyser, der understreger, at standardiserede processer og værktøj reducerer friktionen mellem eksperimentering og produktion.
Kort sagt automatiserer og standardiserer MLOPS hvert trin i maskinlæringens livscyklus, hvilket gør modeller pålidelige, skalerbare og vedligeholdelige i produktionen.

En MLops-arkitektur er en struktureret ramme, der understøtter end-to-end-maskinlæringscyklussen, fra dataindtagelse til implementering og overvågning. Den definerer, hvordan teams organiserer værktøjer, rørledninger og infrastruktur for at levere pålidelige, skalerbare og vedligeholdelige produktions-AI-systemer.
En typisk MLOPS arkitektur omfatter følgende kernekomponenter:
1. Datalag
2. Modeltræningslag
3. Modelregister og versionering
4. Implementeringslag
5. Overvågnings- og observerbarhedslag
6. Governance og sikkerhedslag
Kort sagt organiserer en MLOPS-arkitektur alle lag i maskinlæringens livscyklus, data, træning, implementering, overvågning og styring, så modeller kan implementeres sikkert og vedligeholdes effektivt i stor skala.
MLops er afhængig af en række specialiserede værktøjer til at automatisere, overvåge og administrere maskinindlæring livscyklus. Disse værktøjer er normalt grupperet efter funktion, hvilket hjælper teams med at strømline arbejdsgange, forbedre reproducerbarheden og skalere produktions-AI-systemer.
1. Eksperimentsporing og modelversionering
2. Orkestrering og rørledningsautomatisering
3. Implementering og servering af modeller
4. Overvågning og observabilitet
5. Cloud-platforme til ende-til-ende-MLOP'er
Afslutningsvis er MLOPs-værktøjer organiseret omkring eksperimentering, orkestrering, udrulning, overvågning og cloud-platforme, hvilket gør det muligt for teams at levere pålidelige og skalerbare maskinlæringsmodeller i produktionen.
Effektiv implementering af MLOP'er kræver vedtagelse af praksis, der gør maskinlæringssystemer pålidelige, vedligeholdelige og skalerbare. At følge branchens bedste praksis sikrer, at modeller forbliver nøjagtige, implementeringer er forudsigelige, og teams kan gentage hurtigere.
McKinsey bemærker, at fokus på datakvalitet, styring, CI/CD-integration og automatisering dramatisk forbedrer ydeevnen for AI-systemer i produktionen.
1. Automatiser ende-til-ende-arbejdsgange
2. Version Alt
3. Overvåg modeller kontinuerligt
4. Design til omskoling og løbende forbedring
5. Integrer Governance og Compliance tidligt
6. Tilpas teams omkring delt ejerskab
Ved at følge MLOPs bedste praksis sikrer automatisering, versionering, overvågning, omskoling, styring og teamtilpasning, maskinlæringssystemer forbliver nøjagtige, skalerbare og pålidelige i produktionen.
MLOPs, DevOps og DataOps er relaterede fremgangsmåder, der forbedrer driftseffektiviteten, men de fokuserer på forskellige aspekter af software- og dataarbejdsprocesser. At forstå deres forskelle hjælper teams med at implementere MLOP'er effektivt uden forvirring.
| Practice | Focus | Key Activities | Primary Goal |
|---|---|---|---|
| DevOps | Software development & deployment | CI/CD, infrastructure automation, monitoring, testing | Deliver reliable, scalable software faster |
| DataOps | Data pipelines & quality | Data ingestion, transformation, validation, governance | Ensure accurate, clean, and timely data delivery |
| MLOps | Machine learning systems | Model training, versioning, deployment, monitoring, retraining, governance | Deliver reliable, scalable, and maintainable production AI systems |
Nøgleforskelle:
Kort sagt supplerer MLOPS DevOps og DataOps ved at bygge bro mellem software, data og modeller, hvilket sikrer, at maskinlæringsarbejdsgange er robuste, skalerbare og produktionsklare.
Selv med de rigtige værktøjer kæmper mange organisationer med at implementere MLOP'er på grund af operationelle siloer, kulturelle barrierer og værktøjsspredning.
Imaginary Clouds egen forskning i AI-adoptionsudfordringer fandt ud af, at organisatoriske opkøb og strategisk tilpasning ofte er større blokkere end rent tekniske spørgsmål, hvilket yderligere understregede vigtigheden af at tilpasse MLOP'er til bredere virksomhedsmål.
1. Organisatoriske siloer
2. Værktøjsspredning og integrationskompleksitet
3. Problemer med datakvalitet og tilgængelighed
4. Kulturelle barrierer og kompetencebarrierer
5. Overvågnings- og forvaltningsudfordringer
Kort sagt står teams, der vedtager MLOP'er, over for organisatoriske, tekniske og kulturelle udfordringer, herunder siloer, værktøjskompleksitet, datakvalitetsproblemer og styringskrav. Planlægning af disse hindringer tidligt forbedrer vedtagelsen og sikrer pålideligheden af produktions-AI.
MLops er afgørende for at omdanne maskinlæringseksperimenter til pålidelige, skalerbare produktions-AI-systemer. Ved at kombinere struktureret arkitektur, de rigtige værktøjer og bedste praksis kan teams overvinde udfordringer som modeldrift, datakvalitetsproblemer og implementeringskompleksitet.
Uanset om du lige er begyndt på din MLOPs-rejse eller ønsker at optimere eksisterende arbejdsgange, sikrer vedtagelse af disse principper, at dine modeller forbliver nøjagtige, vedligeholdelige og effektive over tid.
Er du klar til at tage din maskinlæring til produktion med tillid? Kontakt vores team af MLops-eksperter i dag, og find ud af, hvordan vi kan hjælpe dig med at strømline dine AI-operationer.

MLops løser udfordringer inden for produktions-AI, herunder upålidelige implementeringer, modeldrift, dårlig datakvalitet og langsomme iterationscyklusser. Det sikrer, at maskinlæringsmodeller er reproducerbare, skalerbare og vedligeholdelige.
Mens DevOps fokuserer på softwareimplementering og DataOps på datapipelines, bygger MLOPS bro mellem kode, data og modeller. Det sikrer, at maskinlæringsarbejdsgange er pålidelige, automatiserede og produktionsklare.
Ikke alle modeller kræver fulde MLOP'er. Det er mest fordelagtigt, når du implementerer modeller i produktionen, især hvis de har brug for kontinuerlig overvågning, omskoling eller skalering på tværs af teams eller applikationer.
Ja. MLOP'er kan implementeres på cloud-platforme som Google Vertex AI, Azure Machine Learning eller AWS SageMaker samt lokale miljøer afhængigt af overholdelse, infrastruktur og skalerbarhedsbehov.
Populære værktøjer inkluderer MLFlow, Weights & Biases, Kubeflow, Airflow, Seldon, TensorFlow Serving, Prometheus, Grafana og integrerede platforme som AWS SageMaker, Google Vertex AI og Azure ML. Hver tjener specifikke faser af MLOPS livscyklus.

Alexandra Mendes er Senior Growth Specialist hos Imaginary Cloud med 3+ års erfaring med at skrive om softwareudvikling, AI og digital transformation. Efter at have gennemført et frontend-udviklingskursus fik Alexandra nogle praktiske kodningsevner og arbejder nu tæt sammen med tekniske teams. Alexandra brænder for, hvordan nye teknologier former erhvervslivet og samfundet, og hun nyder at omdanne komplekse emner til klart og nyttigt indhold for beslutningstagere.
People who read this post, also found these interesting:







.webp)