
Data mining är en värld i sig, varför det lätt kan bli väldigt förvirrande. Det finns ett otroligt antal verktyg för datautvinning tillgänglig på marknaden. Men medan vissa kan vara mer lämpade för hantering av data mining i Big Data, sticker andra ut för sina datavisualiseringsfunktioner.
Som förklaras i den här artikeln handlar data mining om att upptäcka mönster i data och förutsäga trender och beteenden. Enkelt uttryckt är det processen att konvertera stora uppsättningar data till relevant information. Det är inte mycket nytta med att ha enorma mängder data om vi inte faktiskt vet vad det betyder.
Denna process omfattar andra områden som maskininlärning, databassystem, och statistik. Dessutom kan data mining-funktioner variera kraftigt från datarengöring till artificiell intelligens, dataanalys, regression, klustring etc. Följaktligen utvecklas och uppdateras många verktyg för att uppfylla dessa funktioner och säkerställa Kvaliteten på stora datamängder (eftersom dålig datakvalitet resulterar i dåliga och irrelevanta insikter). Den här artikeln försöker förklara de bästa alternativen för varje funktion och sammanhang. Fortsätt läsa för att ta reda på våra 21 bästa gruvverktyg!
Data mining är en process som omfattar statistik, artificiell intelligens och maskininlärning. Genom att använda intelligenta metoder extraherar denna process information från data, vilket gör den omfattande och tolkbar. Processen med datautvinning gör det möjligt att upptäcka mönster och relationer inom datamängder samt förutsäga trender och beteenden.
Tekniska framsteg har bidragit till snabbare och enklare automatiserad dataanalys. Ju större och mer komplexa datamängderna är, desto större är chansen att hitta relevanta insikter. Genom att identifiera och förstå meningsfulla data kan organisationer utnyttja värdefull information för att fatta beslut och uppnå de föreslagna målen.
Data mining kan tillämpas för flera ändamål, såsom marknadssegmentering, trendanalys, bedrägeriupptäckt, databasmarknadsföring, kreditriskhantering, utbildning, finansiell analys etc. Processen för datautvinning kan delas upp i flera steg enligt varje organisations tillvägagångssätt men i allmänhet innehåller det följande fem steg:
Datalager är processen att samla in och hantera data. Det lagrar data från olika källor i ett arkiv och är särskilt fördelaktigt för operativa affärssystem (t.ex. CRM-system). Denna process sker före datautvinning eftersom den här kommer att upptäcka datamönster och relevant information från lagrade data.
Fördelarna med datalager inkluderar: förbättring av datakvaliteten i källsystem; skydda data från källsystemets uppdateringar; förmåga att integrera flera datakällor; och dataoptimering.
Som tidigare nämnts är data mining en extremt användbar och fördelaktig process som kan hjälpa organisationer att utvecklas strategier baserade på relevanta datainsikter. Data mining korsar många branscher (som försäkring, bank, utbildning, media, teknik, tillverkning etc.) och är kärnan i analytiska insatser.
Processen för datautvinning kan bestå av olika tekniker. Bland de vanligaste är regressionsanalys (förutsägbar), associeringsregelupptäckt (beskrivande), kluster (beskrivande), och klassificering (förutsägbar). Det kan vara fördelaktigt att ha ytterligare kunskap om olika data mining-verktyg när man utvecklar en analys. Tänk dock på att dessa verktyg har olika sätt att fungera på grund av de olika algoritmerna som används i deras design.
Den växande betydelsen av datautvinning inom en mängd olika områden resulterade i kontinuerlig introduktion av nya verktyg och mjukvaruuppgraderingar på marknaden. Följaktligen blir det en tveksam och komplex uppgift att välja rätt programvara. Så innan du fattar några snabba beslut är det viktigt att överväga verksamheten eller forskningskraven.
Denna artikel samlade topp 21 verktyg för datautvinning, som är segmenterade enligt sju kategorier:
Tänk på att vissa av dessa verktyg kan tillhöra mer än en kategori. Vårt urval gjordes enligt den kategori där varje verktyg sticker ut mest. Till exempel, även om Amazon EMR tillhör molnbaserade lösningar, är det samtidigt ett bra verktyg för att hantera Big Data. Innan vi går vidare till de faktiska verktygen tar vi också tillfället i akt att kort förklara skillnaden mellan de två mest populära programmeringsspråken för datavetenskap: R och Python. Även om båda språken är lämpliga för de flesta datavetenskapliga uppgifter, kan det vara svårt (särskilt i början) att veta hur man väljer mellan båda.
Python och R är bland de mest använda programmeringsspråken för datavetenskap. Det ena är inte nödvändigtvis bättre än det andra eftersom båda alternativen har sina styrkor och svagheter. Å ena sidan R utvecklades med statistisk analys i åtanke; å andra sidan Python erbjuder ett mer generiskt tillvägagångssätt för datavetenskap. Vidare är R mer fokuserad på dataanalys och är mer flexibel att använda tillgängliga bibliotek. Däremot är Pythons primära mål distribution och produktion, och det gör det möjligt att skapa modeller från grunden. Sist men inte minst är R ofta integrerat för att köra lokalt, och Python är integrerat med appar. Trots deras skillnader kan båda språken hantera stora mängder data och ha en bred bunt bibliotek.
SPSS, SAS, Oracle Data Mining och R är data mining-verktyg med ett övervägande fokus på den statistiska sidan, snarare än det mer allmänna tillvägagångssättet för datautvinning som Python (till exempel) följer. Till skillnad från de andra statistiska programmen är R dock inte en kommersiell integrerad lösning. Istället är det öppen källkod.
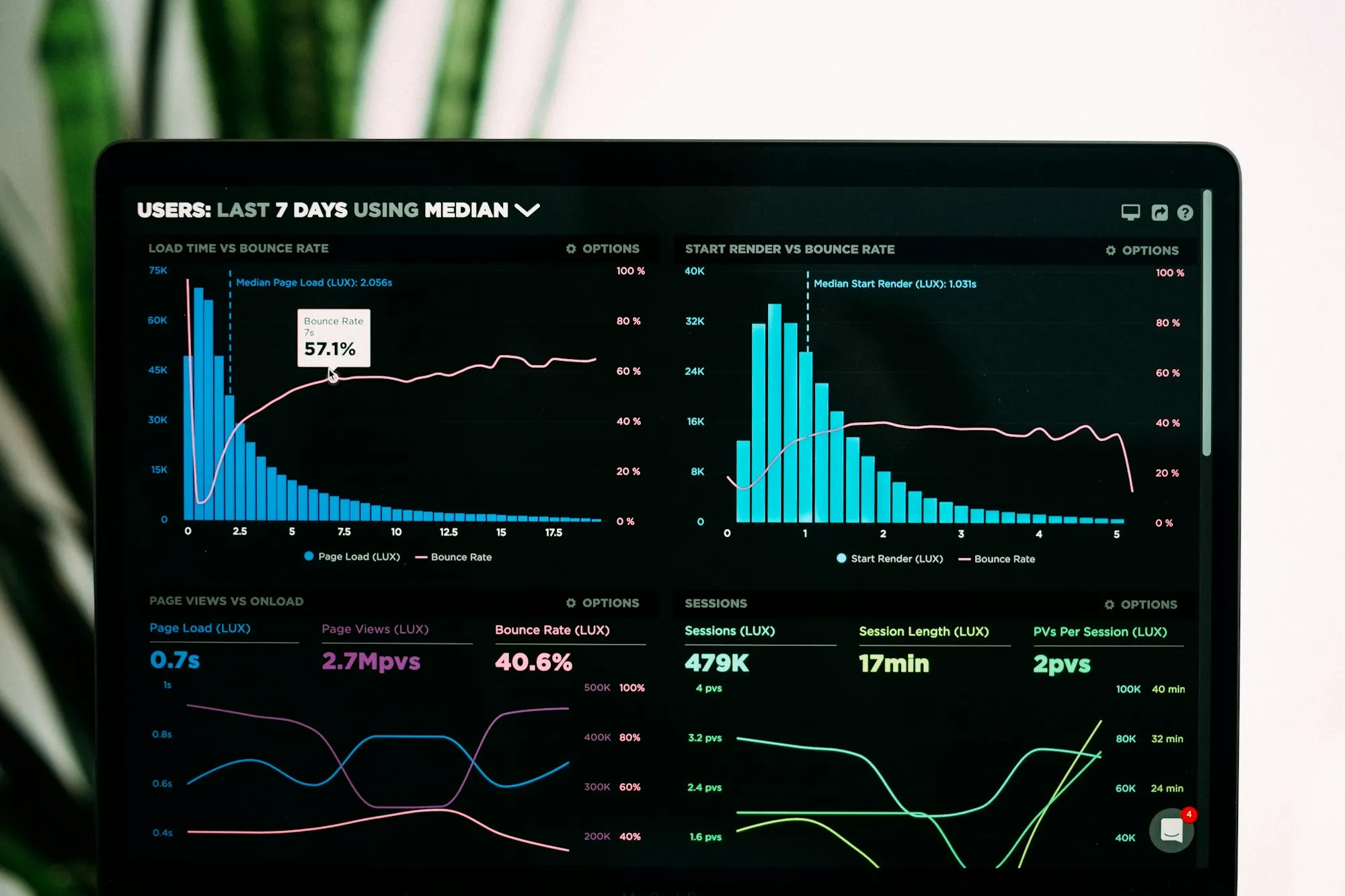
1. IBM SPSSSPSS är en av de mest populära statistiska mjukvaruplattformar. SPSS brukade stå för Statistical Package for the Social Sciences, vilket indikerar dess ursprungliga marknad (områdena sociologi, psykologi, geografi, ekonomi, etc.). IBM förvärvade dock programvaran 2009, och senare, 2015, började SPSS stå för Statistical Product and Service Solutions. Programvarans avancerade förmågor ger ett brett bibliotek med maskininlärningsalgoritmer, statistisk analys (beskrivande, regression, klustring, etc.), textanalys, integration med big data och så vidare. Dessutom tillåter SPPS användaren att förbättra sin SPSS syntax med Python och R genom att använda specialiserade tillägg.
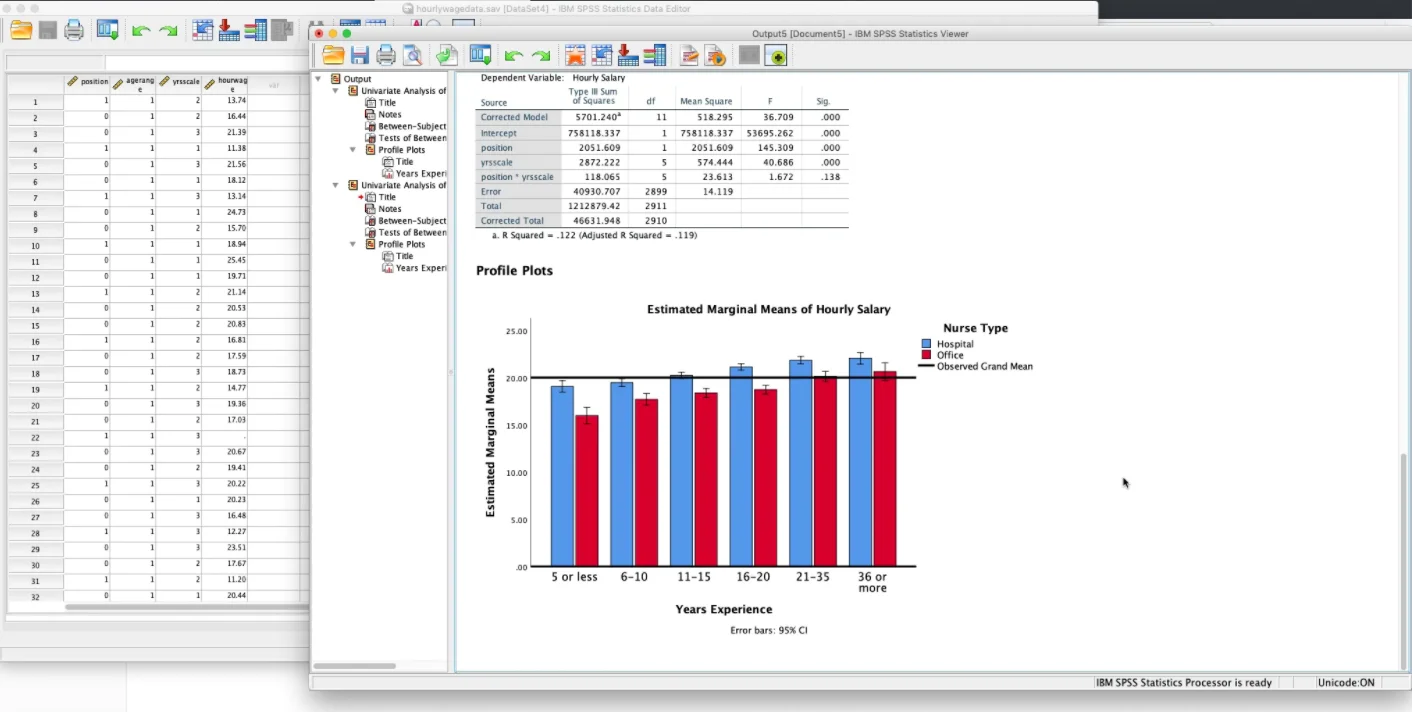
2. RR är en programmeringsspråk och en miljö för statistisk beräkning och grafik. Den är kompatibel med UNIX-plattformar, FreeBSD, Linux, macOS och Windows-operativsystem. Detta fri programvara kan köra en mängd olika statistiska analyser, såsom tidsserieanalys, klustring och linjär och icke-linjär modellering. Dessutom definieras den också som en miljö för statistisk beräkning eftersom det är utformat för att tillhandahålla ett sammanhängande system, som levererar utmärkta data mining-paket. Övergripande, R är ett bra och mycket komplett verktyg som dessutom erbjuder grafiska faciliteter för dataanalys och en omfattande samling mellanverktyg. Det är en öppen källkodslösning för statistisk programvara som SAS och IBM SPSS.
3. SASSAS står för Statistical Analysis System. Detta verktyg är ett utmärkt alternativ för tex gruvdrift, optimering och datautvinning. Det erbjuder många metoder och tekniker för att uppfylla flera analytiska förmågor, som bedömer organisationens behov och mål. Det inkluderar beskrivande modellering (användbart för att kategorisera och profilera kunder), prediktiv modellering (bekvämt för att förutsäga okända resultat) och föreskrivande modellering (användbar för att analysera, filtrera och omvandla ostrukturerade data - som e-post - kommentarfält, böcker och så vidare). Dessutom är dess distribuerade minnesbearbetningsarkitektur gör det också mycket skalbart.
4. Oracles datautvinningOracle Data Mining (ODB) är en del av Oracle Advanced Analytics. Detta datautvinningsverktyg tillhandahåller exceptionella dataförutsägelsesalgoritmer för klassificering, regression, klustring, associering, attributbetydelse och annan specialiserad analys. Dessa egenskaper tillåter ODB för att hämta värdefulla datainsikter och exakta förutsägelser. Dessutom innehåller Oracle Data Mining programmatiska gränssnitt för SQL, PL/SQL, R och Java.
5. KNIMAKNIME står för Konstanz Information Miner. Programvaran följer en öppen källkodsfilosofi och släpptes först 2006. Under de senaste åren har det ofta betraktats som en ledande programvara för datavetenskap och maskininlärning plattformar, som används i många branscher som banker, biovetenskap, förlag och konsultföretag. Ytterligare, det erbjuder både på plats och på moln kontakter, vilket underlättar förflyttning av data mellan miljöer. Även om KNIME implementeras i java, programvaran tillhandahåller också noder så att användare kan köra den i Ruby, Python och R.
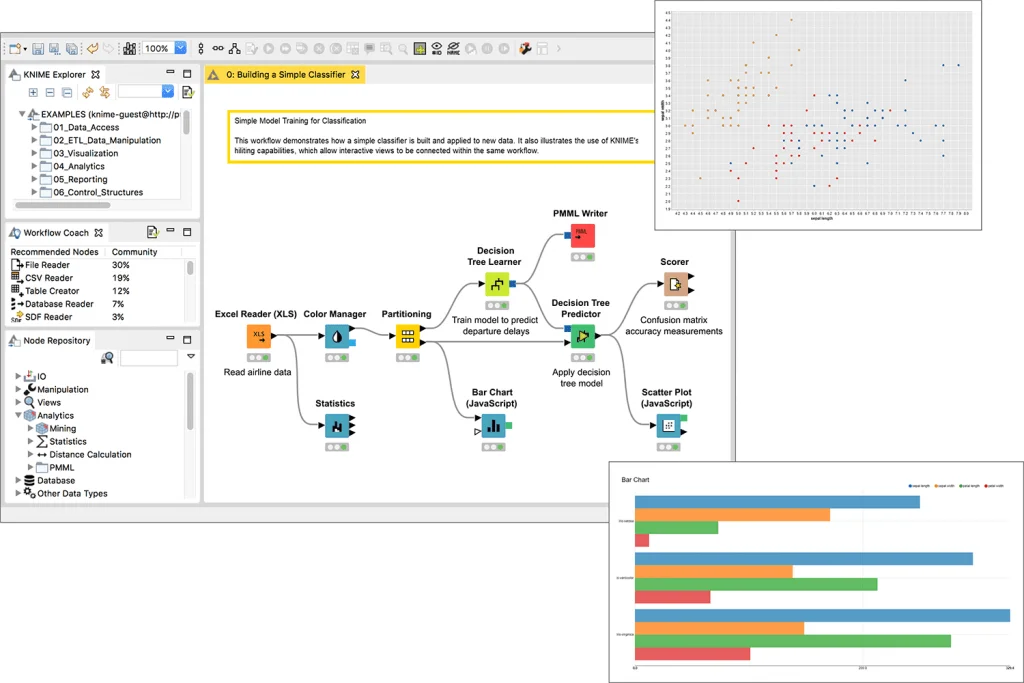
6. RapidMinerSnabb gruvarbetare är ett datautvinningsverktyg med öppen källkod med sömlös integration med både R och Python. Det ger avancerad analys genom att erbjuda många produkter för att skapa nya data mining-processer. Dessutom har den ett av de bästa prediktiva analyssystemen. Denna öppen källkod är skriven i Java och kan integreras med WEKA och R-tool. Några av de mest värdefulla funktionerna inkluderar: fjärranalysbearbetning; skapa och validera prediktiva modeller; flera datahanteringsmetoder tillgängliga; inbyggda mallar och repeterbara arbetsflöden; datafiltrering, sammanslagning och sammanfogning.
7. OrangeOrange är en Python-baserad programvara för datautvinning med öppen källkod. Det är ett bra verktyg för dem som börjar med data mining men också för experter. Förutom dess data mining-funktioner stöder orange också maskininlärningsalgoritmer för datamodellering, regression, klustring, förbehandling och så vidare. Dessutom ger orange en visuell programmeringsmiljö och möjligheten att dra och släppa widgets och länkar.
Stordata avser en enorm mängd data, som kan vara strukturerad, ostrukturerad eller semistrukturerad. Den täcker de fem V-egenskaperna: volym, variation, hastighet, sanning och värde. Big Data involverar vanligtvis flera terabyte eller petabyte data. På grund av dess komplexitet kan det vara svårt (för att inte säga omöjligt) att bearbeta data i en enda dator. Således kan rätt programvara och datalagring vara till stor hjälp för att upptäcka mönster och förutsäga trender. När det gäller data mining-lösningar för big data är dessa våra bästa val:
8. Apache SparkApache Spark sticker ut för sin användarvänlighet vid hantering av big data och är ett av de mest populära verktygen. Den har flera gränssnitt tillgängliga i Java, Python (PySpark), R (SparkR), SQL, Scala och erbjudanden över åttio operatörer på hög nivåvilket gör det möjligt att skriva kod snabbare. Dessutom kompletteras detta verktyg med flera bibliotek, till exempel SQL och DataFrames, Spark Streaming, GRPAHx och MLlib. Apache Spark lockar också uppmärksamhet för sin beundransvärda prestanda, vilket ger en snabb databehandling och dataströmning plattform.

9. Hadoop MapReduceHadoop är en samling verktyg med öppen källkod som hanterar stora mängder data och andra beräkningsproblem. Även om Hadoop är skrivet i java, vilket programmeringsspråk som helst kan användas med Hadoop Streaming. MapReduce är en Hadoop genomförande och en programmeringsmodell. Det har varit en allmänt antagen lösning för att utföra komplexa datautvinning på Big Data. Enkelt uttryckt tillåter det användare att kartlägga och minska funktioner som vanligtvis används i funktionell programmering. Detta verktyg kan utföra stora sammanfogningsoperationer över enorma datamängder. Dessutom erbjuder Hadoop olika applikationer som användaraktivitetsanalys, ostrukturerad databehandling, logganalys, textbrytning etc.
10. QlikQlik är en plattform som adresserar analys och data mining genom ett skalbart och flexibelt tillvägagångssätt. Den har ett lättanvänt dra och släpp-gränssnitt och svarar direkt på ändringar och interaktioner. Dessutom stöder Qlik flera datakällor och sömlösa integrationer med olika applikationsformat antingen via kopplingar och tillägg, inbyggd app eller uppsättningar API:er. Det är också ett utmärkt verktyg för att dela relevant analys med hjälp av ett centraliserat nav.
11. Scikit-LearnScikit-Learn är ett gratis mjukvaruverktyg för maskininlärning i Python, ger enastående datautvinningsfunktioner och dataanalys. Det erbjuder ett stort antal funktioner som klassificering, regression, klustring, förbehandling, modellval och dimensionsreduktion.
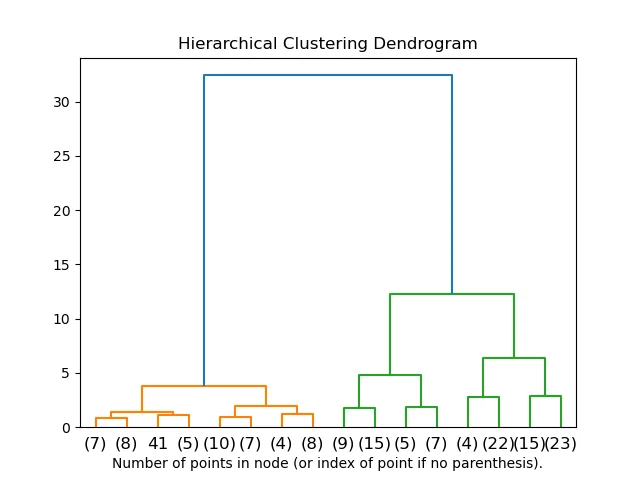
12. Skakel (R)skramla utvecklades i R programmeringsspråk och är kompatibel med operativsystem macOS, Windows och Linux. Det används främst för kommersiella företag och företag, såväl som för vetenskapsman syften (särskilt i USA och Australien). Beräkningskraften för R tillåter denna programvara att tillhandahålla funktioner som klustring, datavisualisering, modellering och annan statistisk analys.
13. Pandor (Python)För datautvinning i Python Pandor är också ett allmänt känt open source-verktyg. Det är ett bibliotek som sticker ut för att arbeta med dataanalys och hantering datastrukturer.
14. H3OH3O är en programvara för datautvinning med öppen källkod som huvudsakligen används av organisationer för att analysera data lagrad i molninfrastruktur. Detta verktyg är skrivet i R språk men är också kompatibel med Python för att bygga modeller. En av de största fördelarna är att H3O möjliggör en snabb och enkel distribution i produktion på grund av Javas språkstöd.
Molnbaserade lösningar blir allt mer nödvändiga för datautvinning. Implementeringen av data mining-tekniker genom molnet gör det möjligt för användare att hämta viktig information från praktiskt taget integrerade datalager, vilket minskar kostnaderna för lagring och infrastruktur.
15. Amazon EMRAmazon EMR är en molnlösning för bearbetning av stora mängder data. Användare använder detta verktyg inte bara för datautvinning men också för att utföra andra datavetenskapliga ansvarsområden som webbindexering, loggfilsanalys, ekonomisk analys, maskininlärning etc. Denna plattform använder en mängd olika Lösningar med öppen källkod (t.ex. Apache Spark och Apache Flink) och underlättar skalbarhet i stora datamiljöer genom att automatisera uppgifter (till exempel ställa in kluster).
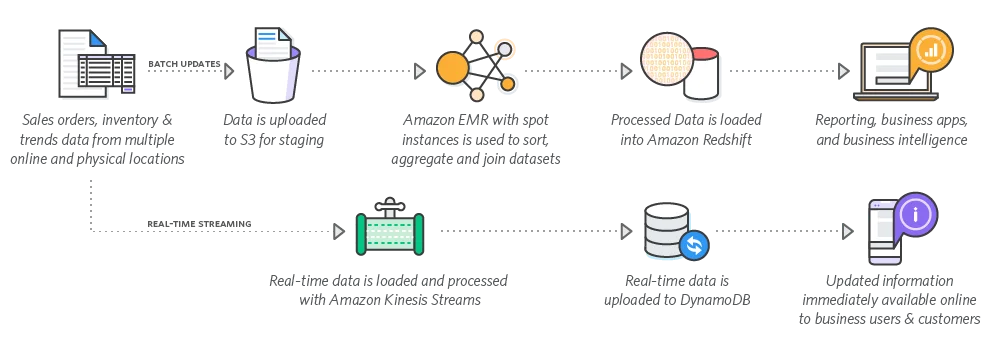
16. Azure MLAzure ML är en molnbaserad miljö gjord för byggnad, utbildning och distribuera maskininlärningsmodeller. För datautvinning kan Azure ML utföra prediktiv analys och låta användare beräkna och manipulera datavolymer från molnplattformen.
17. Googles AI-plattformPå samma sätt som Amazon EMR och Azure ML, Googles AI-plattform Det är också molnbaserat. Denna plattform ger en av största maskininlärningsstaplar. Google AI Platform innehåller flera databaser, maskininlärningsbibliotek och andra verktyg som användare kan använda i molnet för att utföra datautvinning och andra datavetenskapliga funktioner.
Neurala nätverk består av att assimilera data på det sätt som mänsklig hjärna bearbetar information. Med andra ord har vår hjärna miljontals celler (neuroner) som bearbetar extern information och därefter producerar en utgång. Neurala nätverk följer samma princip och kan användas för datautvinning genom att omvandla rådata till relevant information.
18. PyTorchPytorch är ett Python-paket och ett djupt inlärningsramverk baserat på Torch-biblioteket. Det utvecklades ursprungligen av Facebooks AI Research Lab (FAIR), och det är ett mycket välkänt verktyg inom datavetenskap på grund av dess djupa neurala nätverksfunktion. Det gör det möjligt för användare att utföra data mining-stegen för att programmera en hela neurala nätverket: ladda data, förbehandla data, definiera en modell, träna den och utvärdera. Plus, med en stark GPU-acceleration, Torch möjliggör en snabb matrisberäkning. Nyligen, i september 2020, blev detta bibliotek R. Ficklampan för R-ekosystemet inkluderar fackla, facklampa, fackljud och andra förlängningar.
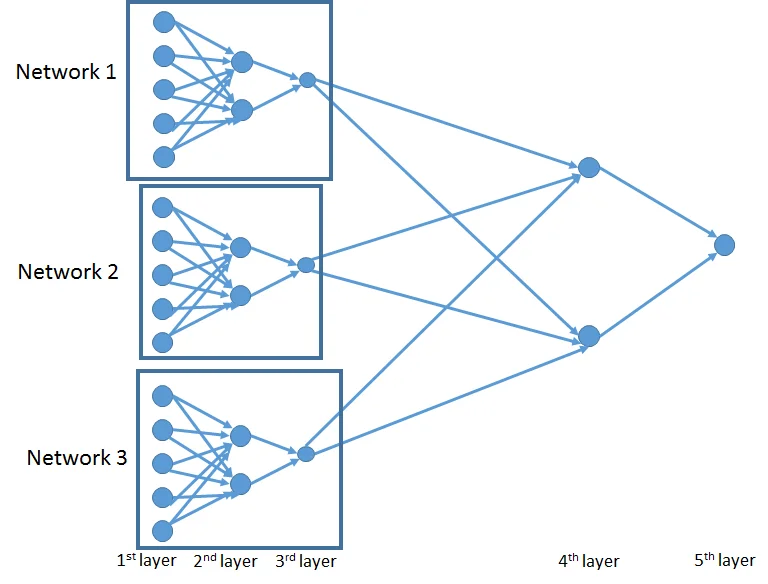
19. TensorFlowPå samma sätt som PyTorch, TensorFlow är också ett Python-bibliotek öppen källkod för maskininlärning, som Google Brain Team ursprungligen utvecklade. Den kan användas för att bygga djupa inlärningsmodeller och har ett högt fokus på djupa neurala nätverk. Förutom en flexibel ekosystem av verktyg, TensorFlow tillhandahåller också andra bibliotek och har en mycket populär gemenskap där utvecklare kan ställa frågor och dela. Trots att det var ett Python-bibliotek introducerade TensorFlow 2017 och R-gränssnitt från RStudio till TensorFlow API.
Datavisualisering är den grafiska representationen av informationen som extraheras från data mining-processen. Dessa verktyg gör det möjligt för användare att ha en visuell förståelse av datainsikter (trender, mönster och avvikelser) genom grafer, diagram, kartor och andra visuella element.
20. MatplotlibMatplotlib är ett utmärkt verktyg för datavisualisering i Python. Detta bibliotek gör det möjligt att använda interaktiva figurer och skapa kvalitetsdiagram (till exempel histogram, spridningsdiagram, 3D-diagram och bilddiagram) som senare kan anpassas (stilar, axelegenskaper, teckensnitt etc.).
21. ggplot2ggplot2 är ett datavisualiseringsverktyg och ett av de mest populära R-paket. Det här verktyget gör det möjligt för användare att ändra komponenter i en plot med en hög abstraktionsnivå. Dessutom tillåter det användare att bygga nästan vilken typ av graf som helst och förbättra grafikens kvalitet såväl som estetik.
För att välja det lämpligaste verktyget är det först viktigt att ha verksamheten eller forskningsmålen väl etablerade. Det är ganska vanligt att utvecklare eller datavetare som arbetar med data mining lär sig flera verktyg. Detta kan vara en utmaning men också mycket användbart för att extrahera relevanta datainsikter.
Som sagt tidigare är de flesta data mining-verktyg beroende av två huvudsakliga programmeringsspråk: R och Python. Var och en av dessa språk tillhandahåller en komplett uppsättning paket och respektive bibliotek för datautvinning och datavetenskap i allmänhet. Trots dessa programmeringsspråks dominans används integrerade statistiska lösningar (som SAS och SPSS) fortfarande mycket av organisationer.


Marknadsföringspraktikant med särskilt intresse för teknik och forskning. På min fritid spelar jag volleyboll och skämmer bort min hund så mycket som möjligt.

Data Scientist med en djup passion för teknik, fysik, och matematik. Jag gillar att lyssna på och göra musik, resa, och åka mountainbikeleder.

Data Scientist som älskar att ta itu med utmanande problem. På fritiden bakar jag, går långa promenader och läser om genomik och näring.
People who read this post, also found these interesting:





.webp)
.webp)
