

Det finns många Relational Database Management Systems (RDBMS) tillgängliga på marknaden, och PostgreSQL och MySQL är bland de två mest populära. Båda alternativen erbjuder många fördelar och är mycket konkurrenskraftiga. Därför är det viktigt att förstå deras skillnader för att välja den lämpligaste för varje enskilt fall.
I den meningen ger den här artikeln en djup jämförelse mellan PostgreSQL och MySQL, med tanke på aspekter som datatyper, ACID-överensstämmelse, index, replikering och mer. Vidare innebär det vilken man ska välja och belyser vikten av att beakta applikationens krav.
PostgreSQL släpptes först i 1996 och skapad vid University of California, vid datavetenskapsavdelningen. För närvarande är dess utveckling under PostgreSQL Global Development Group.
PostgreSQL är ett relationsdatabashanteringssystem med öppen källkod (RDBMS) som också kan betraktas som ett objekt-relationellt databashanteringssystem (ORDBMS) eftersom det stöder vissa objektorienterade funktioner, såsom tabellarv och funktionsöverbelastning.
MySQL introducerades på marknaden i 1995, strax före PostgreSQL. Det är en öppen källkod (tillgänglig under GNU GLP) Relational Database Management System (RDBMS). Dessutom hanteras och ägs denna databas av Oracle Corporation.
Under åren har MySQL byggt upp ett ganska imponerande och pålitligt rykte. Dessutom sticker det också ut i samhället för sin användarvänlighet.
Innan vi går vidare till jämförelsen mellan PostgreSQL vs MySQL, låt oss först förstå hur ORDBMS skiljer sig från RDBMS. MySQL är en rent relationsdatabas. Därför lagras data i ett strukturerat format (med kolumner och rader). Dessutom kan värdena i varje tabell relateras till varandra, och tabeller kan till och med relatera till andra tabeller.
PostgreSQL är en ORDBMS. Dessa system består av en relationsmodell, vilket innebär att det fortfarande är möjligt att relatera värden och tabeller samtidigt som man följer den objektorienterade modellens principer. Således kan ORDBMS inkludera begreppet klasser, objekt och arv.
När det gäller struktur är MySQL och PostgreSQL faktiskt ganska lika. De använder båda tabeller som sin kärnkomponent, vilket innebär att data är organiserade i rader och kolumner. Dessutom integrerar PostgreSQL även lagrade procedurer, vyer, begränsningar, triggers, roller och ytterligare stöd NoSQL. I sin tur erbjuder MySQL nästan samma funktioner (eller mycket identiska sådana), och sedan MySQL 5.7-versionen (2015) började den också inkludera NoSQL-funktioner.
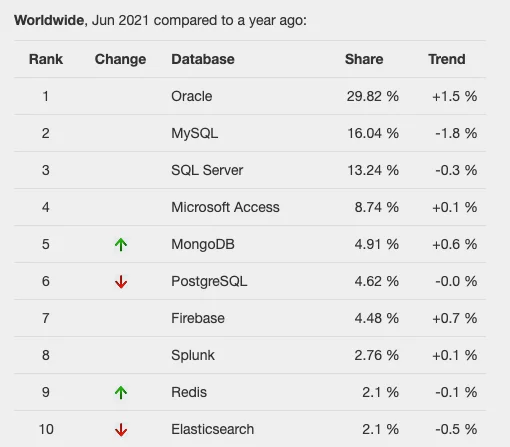
Både PostgreSQL och MySQL är bland de mest populära databaser tillgänglig på marknaden. Men för att vara mer exakt, enligt popularitetsstatistik från maj 2021, är MySQL fortfarande mer populärt än PostgreSQL, eftersom DB-Engines rankinghöjdpunkter.
Dessutom är dessa uppgifter anpassade till TOPDB Toppdatabasindex, som baseras på Googles sökresultat. Enligt indexet är MySQL i den andra positionen och PostgreSQL i den sjätte.
När det gäller community-stöd drar både PostgreSQL och MySQL nytta av aktiva samhällen såväl som omfattande dokumentation stöd.
För närvarande tillåter både PostgreSQL och MySQL utvecklare att arbeta med JSON som datatyp i tabeller. Men saker var inte alltid så. Fram till lanseringen av MySQL 5.7.8-versionen stödde databassystemet inte JSON-filer.
Än så länge, JSON-stöd är fortfarande en av de ledande NoSQL-funktionerna som MySQL har integrerat. Däremot stöder PostgreSQL ytterligare XML, arrayer, användardefinierad typ, och hstore, vilket erbjuder möjligheten att arbeta med fler datatyper än MySQL. Den största fördelen med att ha en mängd olika alternativ tillgängliga är att Det kan öka funktionaliteten. Till exempel, genom att acceptera matriser som en datatyp, kan PostgreSQL också erbjuda värdfunktioner som är kompatibla med dessa arrayer.
Trots fördelarna med att använda alternativa format för att lagra data kan det dock också vara mer komplicerat att implementera sådana dataformat, med tanke på att de inte följer en väl etablerad standard. Därför kanske komponenter som används tillsammans med databasen inte överensstämmer med PostgreSQL-format. Detta behöver inte vara en nackdel, utan snarare något att se upp för.
När det gäller kodning i PostgreSQL kontra MySQL, ett par skillnader bör övervägas. Låt oss börja med skiftlägeskänslighet. Å ena sidan PostgreSQL är skiftlägeskänslig. Detta innebär att utvecklare måste använda stora bokstäver i strängar som de visas i databasen; annars kommer frågan att misslyckas. Å andra sidan är MySQL inte skiftlägeskänslig. Därför finns det inget behov av att kapitalisera strängar medan du frågar.
En annan skillnad när det gäller kodning ligger i karaktärernas uppsättningar och strängar. PostgreSQL tillåter inte UTF-8-syntax; Således finns det inget behov av att konvertera uppsättningar och strängar till denna syntax. Däremot kräver vissa versioner av MySQL denna konvertering.
SQL står för Structured Query Language, och det anses vara standarden när det gäller att fråga dataspråk. Det tillämpas dock inte nödvändigtvis på samma sätt i alla databassystem.
SQL: s grunder är SELECT, INSERT, DELETE och UPDATE. Dessutom kan det också innebära några extra funktioner och skillnader när det gäller syntax.
MySQL är endast delvis SQL-kompatibel eftersom det inte stöder alla funktioner (t.ex. ingen kontrollbegränsning). Men det ger många förlängningar. I sin tur PostgreSQL är mer SQL-kompatibel än MySQL, överensstämmer med de flesta av huvudfunktionerna. För att vara mer exakt stöder PostgreSQL åtminstone 160 av 179 obligatoriska funktioner.
Ju mer omfattande en databas är, desto mer avgörande blir index. Vid hantering av tabeller med miljontals rader kan index vara till stor hjälp och förbättra databasens prestanda. Innan vi tittar på särdragen i varje databassystem, låt oss först ange vad de har gemensamt: PostgreSQL och MySQL erbjuder stöd för B-träd och hashindex. Nu när det är klart låt oss ta en djupgående titt på deras tillvägagångssätt mot index.
Å ena sidan lagras i MySQL de flesta index (PRIMARY KEY, UNIQUE, INDEX och FULLTEXT) i B-träd. Det finns dock några undantag:
Å andra sidan, i PostgreSQL, beaktas indexen sekundära index. Därför lagras indexen separat från tabellens hög, vilket är det huvudsakliga dataområdet. Följaktligen, när du kör en indexskanning, data måste hämtas från både högen och indexet. För att lösa detta besvär utvecklade PostgreSQL stöd för Endast indexskanningar, vilket innebär att utvecklare inte längre behöver be om heap-åtkomst för att fråga ett index. Två åtgärder måste följas för att tillämpa den här metoden: indextypen måste stödja indexskanningar, och frågan kan bara referera till kolumner som lagras i indexet.
För att få ut mesta möjliga av indexskanningsmetoden kan utvecklare skapa en täckningsindex. Täckningsindexet hämtar alla kolumner som behövs. Således innehåller den de kolumner som krävs av en specifik typ av fråga som körs ofta.
Täckningsindex blev endast tillgängliga i PostgreSQL sedan version 9.2 (2012). Men då använde MySQL redan dem för att hämta data genom att skanna indexet utan att behöva röra tabelldata. Sist men inte minst stöder PostgreSQL-index ytterligare funktioner som MySQL ännu inte har utvecklat, såsom partiella index, uttrycksindex och bitmappsindex.
ACID står för atomicitet, konsistens, isolering och hållbarhet. Den beskriver de egenskaper som ett robust databassystem måste ha för att säkerställa transaktionerna är tillförlitliga och konsekventa. Som vi förklarar i vår SQL mot NoSQL artikel, många (för att inte säga de flesta) relationella databashanteringssystem är ACID-kompatibla. Detta betyder inte att NoSQL-databaser inte kan vara ACID-kompatibla. Faktiskt, MongoDB, Apache's CouchDB och IBM Db2 fungerar som ett exempel på NoSQL-databassystem som kan integrera och följa ACID-principer.
MySQL är inte eftersom det inte stöder vissa principer, såsom konsistens, isolering och hållbarhet. MySQL innehåller dock komponenter som InnoDB och NDB Cluster lagringsmotorer, så att utvecklare kan följa ACID-modellen noggrant om de vill.
I jämförelse, PostgreSQL är syra-kompatibel eftersom det ger alla nödvändiga funktioner för att anta ACID-modellen fullt ut. Icke desto mindre kan implementering av dessa funktioner och följa respektive egenskaper sakta ner prestandan.
Som nämnts står ”I” i ACID för ”isolering”, vilket inte är särskilt lätt att uppnå. För riktigt korrekt isolering måste utvecklare se till att transaktioner är serialiserbar, vilket innebär att resultatet av att utföra en uppsättning transaktioner bör vara detsamma som vissa seriella utföranden av dessa transaktioner. Således erbjuder en databas med serialiserbarhet godtyckliga läs-/skrivtransaktioner och kan därmed garantera konsistens. Tyvärr, även om ACID-egenskaper säkerställer tillförlitlighet och konsistens (ett plus för PostgreSQL), kan fullständig isolering också begränsa samtidighet och totalt sett långsammare prestanda (PostgreSQLs nackdel).
PostgreSQL introducerade multi-version concurrency control (MVCC) funktioner först än MySQL, och detta brukade vara en av dess viktigaste fördelar.
MVCC-funktioner ger utvecklare samtidig åtkomst till databasen utan att behöva låsa data. Därför ser varje utvecklare som är ansluten till databasen en ”ögonblicksbild” av data medan de frågar data. Tills en transaktion är fullständigt genomförd ser de andra användarna/utvecklarna inte ändringarna i databasen. Enkelt uttryckt, läsare och författare blockerar inte varandra, och MVCC gör det lättare för dem att interagera. Denna funktion ger”transaktionsisolering”(eller”ögonblicksbildsisolering”, som Oracle kallar det) under varje databassession, vilket undviker att transaktioner verkar inkonsekventa och möjliga konflikter med lås.
I MySQL är det möjligt att dra nytta av MVCC-funktion genom att använda InnoDB. InnoDB är standard MySQL-motorn som gör det möjligt för databassystemet att vara ACID-kompatibelt och ha MVCC. Utvecklare kan välja att använda andra motorer; i alla fall, det kan innebära att förlora dessa två egenskaper.
Som namnet antyder består replikering av en process som gör det möjligt för utvecklare att kopiera data från en databas till replikdatabaser, vilket gör att varje användare kan ha samma informationsnivå. Dessutom innebär replikering flera fördelar, till exempel automatiserade säkerhetskopior, feltolerans, skalbarhet, och förmågan att utföra långa frågor utan att störa huvudklustret.
Båda PostgreSQL och MySQL stöder replikering. I MySQL är replikering enkelriktad asynkron; Således fungerar en databasserver som master, och de andra är ”slavar” (replikerna). Däremot erbjuder PostgreSQL synkron replikering, vilket innebär att den har två databaser som körs samtidigt, och den primära databasen synkroniseras med replikdatabasen. Vidare, kaskad och synkron replikering kan också utföras när du använder PostgreSQL.
En annan aspekt som båda PostgreSQL- och MySQL-stöd är klustring. Clustering använder delad lagring för att replikera en lika stor uppsättning data till varje nod i en miljö. Detta gör det möjligt för databaser att tolerera misslyckanden, på grund av redundansen som skapas genom att replikera data över flera noder i en miljö.
Trots att den har enkelriktad asynkron replikering, MySQL-kluster antar synkron replikering internt. På så sätt tar MySQL bort enstaka felpunkter från systemet och säkerställer att data skrivs till olika noder, vilket undviker negativ påverkan och fel på transaktionerna. Dessutom kan MySQL-utvecklare också använda MySQL Cluster, en multimaster-teknik som prioriterar linjär skalning.
När det gäller klustring stöder PostgreSQL strömmande eller synkrona replikationer och har också Postgres-XL, som är en databasklustermiljö.
När det gäller de skillnader som diskuterats hittills är valet mellan båda databassystemen inte alltid så tydligt. En sak vi vet kan säga säkert är att oavsett vad, det finns inget fel svar. Båda databassystemen är populär och har ett pålitligt rykte. Det ena kan dock vara mer lämpligt än det andra, beroende på sammanhanget.
Som nämnts är MySQL en RDBMS, medan PostgreSQL är en ORDBMS eftersom den innehåller objektorienterade funktioner, såsom funktionsöverbelastning och tabellarv. Denna skillnad i sig kan räcka för att vissa utvecklare ska välja PostgreSQL, med tanke på att det gör det lättare för utvecklare att modellera komplexa applikationsobjektstrukturer.
Dessutom, PostgreSQL är mer SQL-kompatibel än konkurrentalternativet och är också känd för att upprätthålla dataintegritet vid transaktioner, anta ACID-modellen. Tvärtom, för att vara ACID-kompatibel, kräver MySQL användning av InnoDB och NDB Cluster lagringsmotorer. Men att inte behöva vara ACID-kompatibel kan nödvändigtvis också göra MySQL snabbare när det gäller att läsa data.
Att välja MySQL har faktiskt också sina fördelar. Hittills är det fortfarande mer populärt än PostgreSQL och drar nytta av en omfattande gemenskap samt ett stort antal verktyg från tredje part. Ett annat stort plus är att MySQL sticker ut för att vara snabb, pålitlig och okomplicerad databas Ett system som är lätt att förstå och sätta upp. Vidare har MySQL under de senaste åren fortsatt att introducera relevanta funktioner (som MVCC).
Med tanke på allt är PostgreSQL rikare när det gäller inbyggda funktioner, och det har visat sin förmåga att hantera komplexa frågor (t.ex. underfrågor, filtrerade resultat, kopplingar etc.), samt omfattande databaser. Men om prioriteringen är att ha ett databassystem som är snabbt, pålitligt och ganska enkelt att hantera, är MySQL också ett utmärkt val.
I sista hand, valet mellan PostgreSQL vs MySQL kommer alltid att bero på applikationens krav. Till exempel, när du hanterar en databas med mycket ostrukturerad data, kan det vara mer fördelaktigt att välja PostgreSQL eftersom det stöder fler datatyper.
Jämförelsen mellan PostgreSQL vs MySQL bör inte fokusera på vilken som är bättre utan snarare på att välja det ena eller det andra för en specifik applikation. Med andra ord, applikationskrav bör alltid anpassas till databassystemets egenskaper och förmågor.
För att kunna välja klokt är det därför viktigt att förstå hur PostgreSQL och MySQL skiljer sig åt när det gäller kritiska aspekter och hur utvecklare kan få ut det mesta av varje alternativ.

Marknadsföringspraktikant med särskilt intresse för teknik och forskning. På min fritid spelar jag volleyboll och skämmer bort min hund så mycket som möjligt.

Mjukvaruutvecklare som älskar backend-sidan, smidig och RoR-beroende. En fotbollsfans och en entusiast av cykling. Låt oss rida!
People who read this post, also found these interesting:







.webp)