

Det finns många databaser tillgängliga på marknaden, och att veta vilken man ska välja kan vara extremt svårt. Ett utmärkt sätt att börja utesluta vissa alternativ är att först ha en klar förståelse för Huvudskillnaderna mellan SQL- och NoSQL-databaser.
I den här artikeln presenterar vi en detaljerad jämförelse mellan dessa två olika typer av databaser angående struktur, schema, skalbarhet, fråga och transaktioner.
Dessutom förklarar vi när du ska använda SQL eller NoSQL databaser och ger vidare ett historiskt sammanhang för dem som är intresserade av att veta hur denna dikotomi började.
SQL är ett programmeringsspråk; dock, det är inte ett allmänt programmeringsspråk som java, Javaskript, eller Python. Istället följer SQL ett specifikt syfte: att komma åt och manipulera data.
För att vara mer exakt står SQL för Strukturerat frågespråk. Det är ett frågespråk som gör det möjligt att hämta specifika data från databaser, och i den meningen är det utformat för att komma åt, lagra och manipulera relationsdatabaser.
En relationsdatabas är en typ av databas (vanligtvis organiserad i tabeller) som möjliggör igenkänning och tillgång till uppgifter i relation till en annan bit data i samma databas. Med andra ord lagrar den relaterade data över flera tabeller, som är organiserade i kolumner och rader, och tillåter användaren att fråga data (eller information) från olika tabeller samtidigt.
En relationsdatabas är en databas som följer Relationsmodell av data. För att upprätthålla en relationsdatabas, a Relationsdatabashanteringssystem (RDBMS) används. Följaktligen, för att fungera på det systemet, tenderar många databaser att använda SQL för att hantera och fråga databasen. Således, SQL är ett språk som möjliggör kommunikation med data i en RDBMS.
En viktig aspekt att rensa ut är att SQL inte är ett databassystem i sig. Sanningen ska sägas, när jämföra SQL vs NoSQLDe viktigaste skillnaderna som bedöms är relationsdatabaser kontra icke-relationsdatabaser (samt distribuerade databaser).
En annan aspekt att tänka på är att SQL inte är det enda programmeringsspråket som kan fråga relationsdatabaser, men det är definitivt det mest populära. Därför används termerna ”SQL-databaser” och ”relationsdatabaser” ofta omväxlande. MySQL, PostgreSQL, Microsoft SQL Server och Oracle-databas är bland de mest kända RDBMS som använder SQL.
NoSQL avser icke-relationella databaser och distribuerade databaser. NoSQL kan också stå för ”Inte bara SQL” för att markera att vissa NoSQL-system också kan stödja SQL-frågespråk. Faktum är att innan du går vidare är det viktigt att komma ihåg att NoSQL inte nödvändigtvis betyder att en databas inte stöder SQL. Istället, det betyder att databasen inte är en RDBMS.
Medan traditionella RDBMS förlitar sig på SQL-syntax för att lagra och fråga data, å andra sidan, NoSQL-databassystem använda annan teknik och programmeringsspråk för att lagra strukturerad, ostrukturerad eller semistrukturerad data.
Den Relationsmodell av data introducerades 1970 av E.F. Codd. Fyra år senare (1974) introducerade Raymond Boyce och Donald Chamberlin SQL, som ursprungligen utvecklades för att fråga IBM:s system R, ett databashanteringssystem.
Det tog inte lång tid tills SQL blev en enorm framgång bland relationsdatabassystem på grund av dess otroliga användbarhet och förmåga att minska duplicering av data. Således ansågs det snart och under lång tid vara det dominerande språket för relationella databassystem. Men sedan hände en liten sak: World Wide Web, 1989.
Konsekvenserna? Mer data. Mycket mer data. Som vi vet var Internets tillväxt inte långsam, och när nya källor och datamängder fortsatte att störa vår värld började relationsdatabaser kämpa.
I början av 2000-talet, för att hantera denna enorma mängd data, icke-relationella system, som Storbord (från Google, 2006) och Dynamo (av Amazon, 2007), började göra sitt eget sätt. Fokus låg på skalbarhet och snabb tillämpning.
Under dessa år, och när fler icke-relationella databaser började dyka upp, begreppet NoSQL blev mycket populärt (även om termen myntades först 1998 av Carlo Strozzi, och icke-relationella databaser finns sedan 60-talet).
Har början av århundradet representerat Slutet på SQL och följaktligen av relationsdatabaser? - Nej, naturligtvis inte. Av två skäl:
Tiden har lärt oss att SQL-databaser inte är bättre eller sämre än NoSQL-databaser. De är helt enkelt föredragna och mer lämpade för olika tillämpningar angående databashanteringssystem (DBMS).
Enligt 2021 DZone Data Persistence Trendrapport (bild nedan), relationsdatabaser är de mest populära DBMS. NoSQL-databaser hänvisar dock till alla icke-relationella DBMS: er (inklusive graf, dokumentorienterad, nyckelvärde, kolumnorienterad och andra). Därför, i kombination, NoSQL-databaser är för närvarande mer populära än relationsdatabaser.
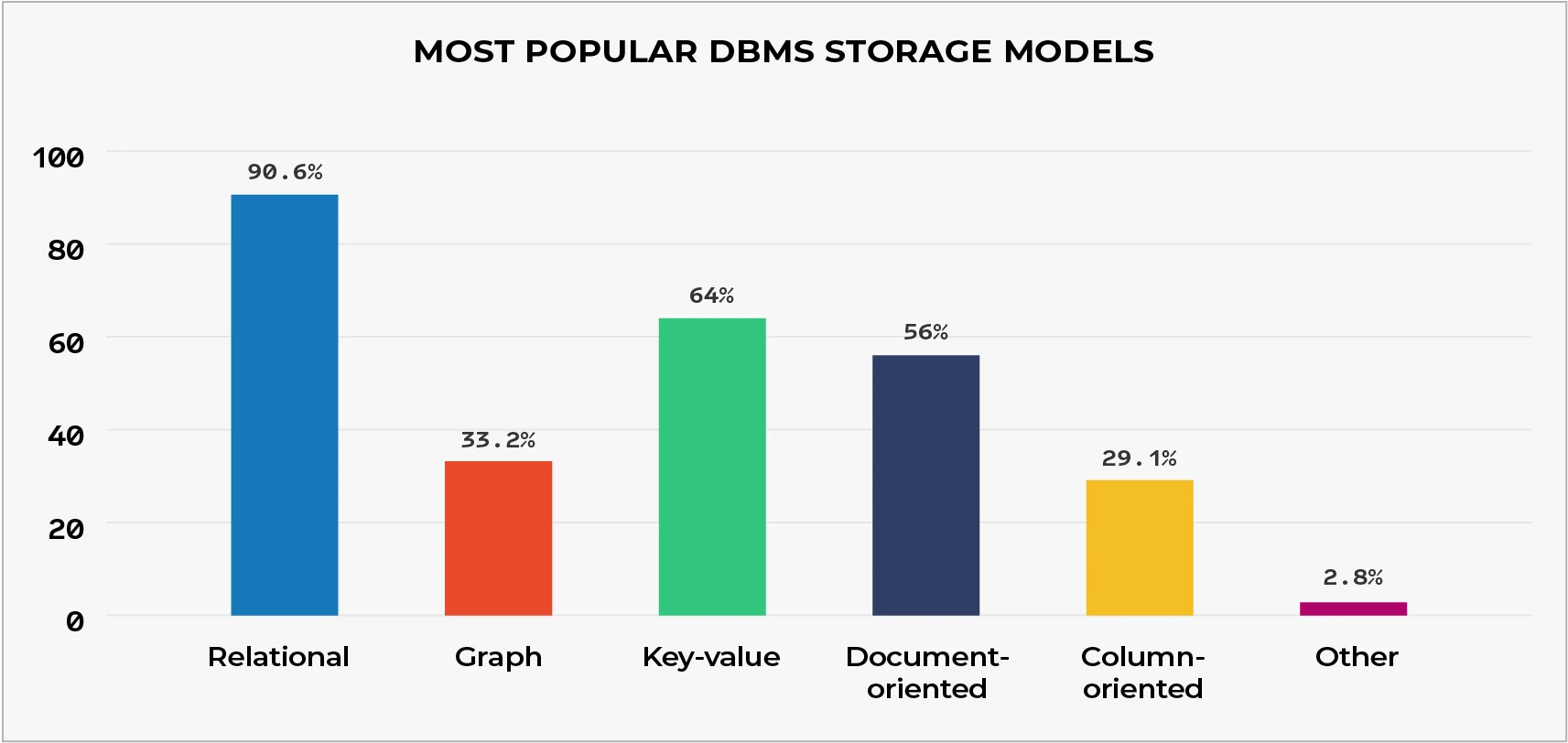
Sammanfattningsvis rätt val när det gäller SQL mot NoSQL beror först och främst på att veta vilken typ av databas som passar varje företags eller organisations syften bättre. Innan vi går vidare till när vi ska använda var och en, låt oss först titta på deras skillnader.
SQL-databaser organiserar och lagrar data efter tabeller med fasta kolumner och rader. Däremot kan NoSQL-databaser lagras på olika sätt:
SQL-databaser kräver en fast fördefinierat schema, och alla data måste följa en liknande struktur. Följaktligen krävs mycket förberedelser beträffande systemet i förväg. Dessutom äventyras flexibiliteten, med tanke på att potentiella ändringar i strukturen kan vara komplexa, mycket komplicerade och kan störa systemet.
I sin tur följer NoSQL-databaser a dynamiskt schema för ostrukturerad data. Eftersom det inte kräver en fördefinierad struktur är ändringar lättare att utföra. Därför har NoSQL-databaser större flexibilitet; flexibilitet kan dock också äventyra tillförlitligheten trots fördelarna.
När det gäller skalbarhet, SQL-databaser följer ett vertikalt tillvägagångssätt, även känd som ”scale-up”. I databaser innebär det att det är möjligt att öka mängden data i en enda server genom att lägga till mer ström till en befintlig maskin genom att till exempel använda en CPU, RAM eller SSD.
Å andra sidan NoSQL-databaser skalas horisontellt (även känd som ”skalning ut”) eftersom de skalas över råvaruservrar, vilket innebär att fler servrar läggs till i resurspoolen och data kan distribueras över dessa resurser.
JOIN-operationer gör det möjligt att ansluta och relatera bitar av data. I allmänhet är NoSQL-databaser (kan men) inte utformade för att stödja JOIN effektivt. Objekt kan finnas på olika servrar i icke-relationella databassystem utan att oroa sig för att sammanfoga tabeller från flera servrar.
Således möjliggör NoSQL enkel skalning genom att dela data och ha ett routinglager som kan omdirigera frågan till lämplig skärv, vilket gör NoSQL-databaserna mycket skalbara och snabba att fråga. Det äventyrar dock dataintegriteten och följer inte en ACID-strategi.
”Utskalning” i RDBMS är i allmänhet svårare att implementera på grund av ACID-koncepten relationsdatabaser följer. För att ett RDBMS med flera servrar ska upprätthålla dataintegritet över transaktioner, skulle det kräva en snabb backend-kommunikationskanal. Denna kanal måste synkronisera alla skrivningar och transaktioner, samt förhindra eventuella dödläge.
Även om det är tekniskt möjligt att skala ut i RDBMS, skalas dessa databassystem vanligtvis upp för att säkerställa dataintegritet och ACID-principer istället för att distribuera data över flera servrar.
Som tidigare nämnts har SQL funnits länge; Således beundras det allmänt som ett moget och populärt språk som drar nytta av ett pålitligt rykte. Det är otroligt effektivt när det gäller att fråga data, manipulera och hämta data från relationsdatabaser. Dessutom sticker det också ut för att vara deklarativt och lätt.
En annan stor fördel med SQL är att det är relativt lätt att lära sig, vilket innebär att marknadsförare och affärsanalytiker kan använda det utan att nödvändigtvis behöva teknisk personalens hjälp.
När det gäller kör NoSQL-frågor, det kanske inte är lika enkelt som SQL-databaser eftersom det vanligtvis behöver utföra extra databehandling och inte har ett deklarativt frågespråk. Därför utförs dessa uppgifter vanligtvis av datavetare eller utvecklare.
Allt som allt, hur man kör frågor i NoSQL-databaser Det beror mycket på databasen i fråga. Till exempel, i MongoDB, för att begära data från JSON-dokumentdatabasen, är det nödvändigt att ange dokumenten med de egenskaper som resultaten ska matcha och tillämpa följande funktion: db.collection.find (). Andra populära lösningar kan vara att skapa frågefunktionaliteten direkt i applikationslagret (och inte i databasskiktet) eller implementera MapReduce.
SQL-databaser följer vanligtvis SYRA-egenskaper när det gäller transaktioner. ACID står för Atomic, Consistent, Isolated och Durable. Låt oss ta en närmare titt för att förstå mer exakt vad det betyder:
Som man kan se, ACID-modellen säkerställer att en transaktion är tillförlitlig och konsekvent. Därför är databaser som följer denna modell bäst lämpade för organisationer och företag som inte kan riskera ogiltiga och avbrutna datatransaktioner eller andra fel (t.ex. finansinstitut).
Relationsdatabashanteringssystem (som MySQL, SQLite, PostgreSQL, etc.) är ACID-kompatibla. Men även om metoden för NoSQL-databaser vanligtvis strider mot ACID-principer, kan vissa NoSQL-databaser (t.ex. MongoDB, IBMs Db2 och Apache's CouchDB) också integrera och följa ACID-regler.
I icke-relationella databaser är datapålitligheten och konsistensen av att vara ACID-kompatibel vanligtvis inte en främsta prioritet, med tanke på att det kan äventyra hastighet och hög tillgänglighet.
För NoSQL-databaser tenderar prioriteringen att fokusera på flexibilitet och på en hög transaktionshastighet. Av denna anledning är BASE-modell följs i många NoSQL-databassystem. Det står för Fundamentally Available, Soft state och Så småningom konsekvent.
NoSQL-databaser följer vanligtvis BASE-modellen, vilket ger mer elasticitet än ACID-modellen. Som nämnts är ACID bättre för företag och organisationer som behöver säkerställa varje transaktions konsistens, förutsägbarhet och tillförlitlighet.
Däremot är BASE-modellen mer lämplig för företag som prioriterar hög tillgänglighet, skalbarhet och flexibilitet för datatransaktioner. Till exempel hanterar en app för sociala nätverk enorma mängder data som ofta inte är särskilt välstrukturerade; i så fall kan en BASE-modell göra det enklare (och snabbare) att lagra data.
Nu när vi har täckt Huvudskillnaderna mellan SQL och NoSQL, det är dags att förklara när man ska använda det ena eller det andra. Innan ett slutligt beslut fattas är det viktigt att överväga följande aspekter:
När det gäller den första aspekten är SQL-databaser ett lämpligare alternativ än NoSQL när data integritet och konsistens är nyckeln inom en organisation.
Det finns ofta en missuppfattning att relationsdatabaser inte är ett bra alternativ för att hantera stora mängder data. Det är inte exakt sant. Många SQL-databaser, som PostgreSQL och MySQL, kan verkligen hantera mycket respektfulla mängder data.
Men eftersom RDBMS som använder SQL har ett fast schema och kräver att data är strukturerad, kommer det förmodligen att bli mycket utmanande att hålla jämna steg med det nödvändiga underhåll, smidighet och prestanda som till exempel ett företag som hanterar Big Data kan kräva.
Vid första anblicken kan det tyckas att ha ett fast schema är begränsande. Tja, igen, det beror på syftet. Att ha en fördefinierad schemadatabas gör också SQL-databaser är det lämpligaste alternativet för hantering av lönehanteringssystem eller till och med för hantering av flygbokningar. Faktum är att de flesta bankinstitut förlitar sig på ett SQL-databassystem.
Som vi tidigare har förklarat, relationsdatabaser är vanligtvis ACID-kompatibla, vilket innebär att datatransaktioner säkerställer integritet, giltighet och tillförlitlighet. Dessutom kan SQL begränsa vissa funktioner, men det är också en mycket mogen teknik.
Dessutom erbjuder en relationsdatabas och SQL mycket stöd när det gäller ad hoc-frågor. Denna typ av databaser är vanligtvis lättare att hantera. Eftersom SQL är ett populärt frågespråk och relativt lätt att lära sig behöver det inte nödvändigtvis ett stort team av ingenjörer för att underhålla det.
NoSQL-databaser kan lagra olika typer av data och behöver inte vara lika strukturerade som SQL-databaser. Därför möjliggör icke-relationella databaser stor anpassningsförmåga och flexibilitet, vilket gör det till ett mer lämpligt val när hantera stora uppsättningar ostrukturerade och orelaterade data.
Vanligtvis, ju mer omfattande datauppsättningen är, desto mer sannolikt är en NoSQL-databas ett bättre alternativ. Icke-relationella databaser tenderar att utmärka sig på krav på skalbarhet och tillgänglighet, som är idealisk för sociala nätverk och realtidsapplikationer (t.ex. onlinespel, snabbmeddelanden), till exempel.
NoSQL-databaser kräver programmeringskunskap. Till skillnad från SQL, som också kan läras av personal från andra områden som förvaltning och marknadsföring, behöver NoSQL-databaser vanligtvis någon med bakgrund i kodning och förmågan att förvärva andra språk enligt de databassystem som används.
Att välja rätt databas är inte ett rakt och exakt beslut, inte ens för experter. Att bestämma om man ska gå till relationella eller icke-relationella databaser är ett bra sätt att börja. Ändå är det också viktigt att ta hänsyn till de många SQL- och NoSQL-alternativ tillgängliga på marknaden.
Till exempel, för mycket ostrukturerad data, kan CouchDB eller MongoDB vara ett bra alternativ, men kanske för hög tillgänglighet, Redis och Cassandra kan vara lämpligare. Och det här är alla icke-relationella databassystem!
Å andra sidan SQL-databaser erbjuder många fördelar avseende datatransaktioner och övergripande dataintegritet. Dessutom kan relationsdatabasernas relationer lätt identifieras och definieras, vilket gör det enkelt att identifiera kritiska insikter.


Marknadsföringspraktikant med särskilt intresse för teknik och forskning. På min fritid spelar jag volleyboll och skämmer bort min hund så mycket som möjligt.

VD @ Imaginary Cloud och medförfattare till boken Product Design Process. Jag gillar mat, vin och Krav Maga (inte nödvändigtvis i denna ordning).
People who read this post, also found these interesting:





.webp)
.webp)
