
MLOps (Machine Learning Operations) is a set of practices that enables organisations to deploy, manage, and scale machine learning models in production. It connects data science with engineering by adding automation, monitoring, and governance across the machine learning lifecycle.
As machine learning moves into production AI systems, teams face challenges such as model drift, unreliable deployments, and slow iteration. MLOps addresses these issues through a well-defined architecture, tools, and best practices that make machine learning reliable and maintainable at scale.
MLOps (Machine Learning Operations) is a set of practices that standardises and automates the development, deployment, monitoring, and maintenance of machine learning models in production. Its goal is to make machine learning systems reliable, scalable, and repeatable, in the same way DevOps does for traditional software, while accounting for the unique challenges of data and models.
At its core, MLOps sits at the intersection of machine learning, software engineering, and operations. It covers the full machine learning lifecycle, from data ingestion and model training to deployment, monitoring, and continuous improvement. Unlike traditional software, machine learning systems depend not only on code, but also on data, features, and model parameters, all of which can change over time and affect performance.
MLOps emerged as organisations realised that training a model is only a small part of delivering value with AI. In real-world environments, models must be versioned, tested, deployed safely, monitored for issues such as model drift, and retrained as data evolves. Without MLOps, teams often struggle with manual deployments, inconsistent results, and models that degrade silently in production.
Major cloud and research organisations define MLOps in similar terms:
In practice, MLOps enables teams to move from experimental notebooks to production AI systems that can be trusted, audited, and improved over time—making it a foundational capability for any organisation serious about using machine learning in real products and services.
MLOps is important because many machine learning initiatives stall or fail at deployment due to fragmented workflows and a lack of operational discipline, a problem well documented in industry analyses. A structured MLOps approach aligns teams and tech, reducing time to production and ongoing maintenance risk. Organisations with clear operational frameworks often see far faster adoption and ROI.
Additionally, MLOps accelerates time-to-value for machine learning initiatives. A Forbes Technology Council analysis notes that ML operational chaos, such as slow deployment cycles and unclear model ownership, significantly delays time to production, reinforcing the need for dedicated operational frameworks.
In short, MLOps is what makes production AI sustainable. It allows teams to move faster without sacrificing reliability, ensures models remain accurate over time, and provides the controls needed to operate machine learning systems with confidence at scale.
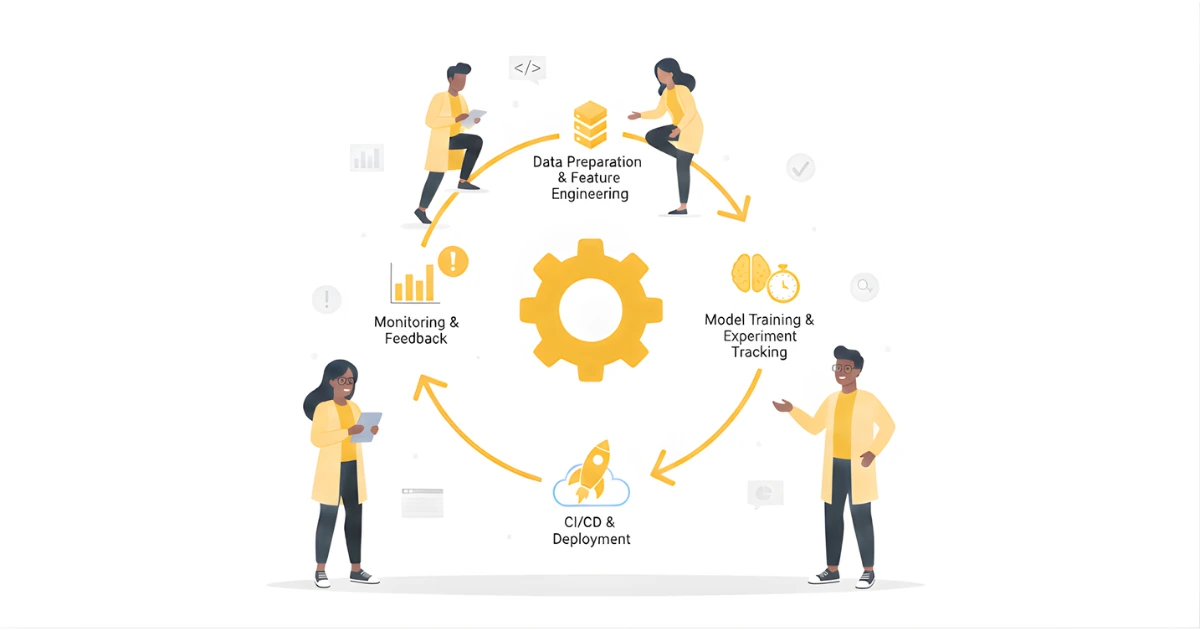
MLOps works by managing the entire machine learning lifecycle, from data collection to production deployment and continuous improvement. By applying structured processes and automation, MLOps ensures models are reliable, reproducible, and scalable. The lifecycle can be summarised in six key stages:
Machine learning begins with data. MLOps pipelines collect data from multiple sources, validate it, and store it in a format suitable for training. Automated pipelines help ensure data quality and consistency, reducing errors before they affect models.
Raw data is transformed into features that models can learn from. MLOps ensures feature pipelines are versioned, reproducible, and monitored, so that the same transformations can be applied consistently in training and production.
Data scientists train models using various algorithms and hyperparameters. MLOps integrates experiment tracking, model versioning, and automated testing to compare performance and maintain reproducibility. Tools like MLflow and Weights & Biases are commonly used for this stage.
Before deployment, models are validated against unseen data to measure accuracy, fairness, and reliability. MLOps pipelines include automated tests and performance checks to prevent regression or bias in production models.
Models are deployed into production using automated CI/CD pipelines. This ensures repeatable, safe, and fast deployment across environments. Deployment strategies can include A/B testing, canary releases, or rolling updates to minimise risk.
After deployment, models are monitored for performance drift, data drift, and errors. MLOps enables automatic retraining or alerts when metrics degrade. Governance practices ensure compliance, logging, and auditing for production ML systems.
The need for automation and consistency in operational workflows is echoed across industry analyses, which emphasise that standardised processes and tooling reduce the friction between experimentation and production.
In short, MLOps automates and standardises every step of the machine learning lifecycle, making models reliable, scalable, and maintainable in production.

An MLOps architecture is a structured framework that supports the end-to-end machine learning lifecycle, from data ingestion to deployment and monitoring. It defines how teams organise tools, pipelines, and infrastructure to deliver reliable, scalable, and maintainable production AI systems.
A typical MLOps architecture includes the following core components:
1. Data Layer
2. Model Training Layer
3. Model Registry and Versioning
4. Deployment Layer
5. Monitoring and Observability Layer
6. Governance and Security Layer
In short, an MLOps architecture organises all layers of the machine learning lifecycle, data, training, deployment, monitoring, and governance, so models can be deployed safely and maintained effectively at scale.
MLOps relies on a range of specialised tools to automate, monitor, and manage the machine learning lifecycle. These tools are usually grouped by function, helping teams streamline workflows, improve reproducibility, and scale production AI systems.
1. Experiment Tracking and Model Versioning
2. Orchestration and Pipeline Automation
3. Model Deployment and Serving
4. Monitoring and Observability
5. Cloud Platforms for End-to-End MLOps
In conclusion, MLOps tools are organised around experimentation, orchestration, deployment, monitoring, and cloud platforms, enabling teams to deliver reliable and scalable machine learning models in production.
Implementing MLOps effectively requires adopting practices that make machine learning systems reliable, maintainable, and scalable. Following industry best practices ensures models stay accurate, deployments are predictable, and teams can iterate faster.
McKinsey notes that focusing on data quality, governance, CI/CD integration, and automation dramatically improves the performance of AI systems in production.
1. Automate End-to-End Workflows
2. Version Everything
3. Monitor Models Continuously
4. Design for Retraining and Continuous Improvement
5. Embed Governance and Compliance Early
6. Align Teams Around Shared Ownership
By following MLOps best practices, automation, versioning, monitoring, retraining, governance, and team alignment ensure machine learning systems remain accurate, scalable, and reliable in production.
MLOps, DevOps, and DataOps are related practices that improve operational efficiency, but they focus on different aspects of software and data workflows. Understanding their differences helps teams implement MLOps effectively without confusion.
| Practice | Focus | Key Activities | Primary Goal |
|---|---|---|---|
| DevOps | Software development & deployment | CI/CD, infrastructure automation, monitoring, testing | Deliver reliable, scalable software faster |
| DataOps | Data pipelines & quality | Data ingestion, transformation, validation, governance | Ensure accurate, clean, and timely data delivery |
| MLOps | Machine learning systems | Model training, versioning, deployment, monitoring, retraining, governance | Deliver reliable, scalable, and maintainable production AI systems |
Key Differences:
In short, MLOps complements DevOps and DataOps by bridging the gap between software, data, and models, ensuring machine learning workflows are robust, scalable, and production-ready.
Even with the right tools, many organisations struggle to implement MLOps due to operational silos, cultural barriers, and tool sprawl.
Imaginary Cloud’s own research into AI adoption challenges found that organisational buy‑in and strategic alignment are often larger blockers than purely technical issues, further emphasising the importance of aligning MLOps with broader enterprise goals.
1. Organisational Silos
2. Tool Sprawl and Integration Complexity
3. Data Quality and Availability Issues
4. Cultural and Skills Barriers
5. Monitoring and Governance Challenges
In short, teams adopting MLOps face organisational, technical, and cultural challenges, including silos, tool complexity, data quality issues, and governance requirements. Planning for these obstacles early improves adoption and ensures the reliability of production AI.
MLOps is essential for turning machine learning experiments into reliable, scalable production AI systems. By combining structured architecture, the right tools, and best practices, teams can overcome challenges such as model drift, data quality issues, and deployment complexity.
Whether you’re just starting your MLOps journey or looking to optimise existing workflows, adopting these principles ensures your models remain accurate, maintainable, and impactful over time.
Ready to take your machine learning to production with confidence? Contact our team of MLOps experts today and discover how we can help you streamline your AI operations.

MLOps solves challenges in production AI, including unreliable deployments, model drift, poor data quality, and slow iteration cycles. It ensures machine learning models are reproducible, scalable, and maintainable.
While DevOps focuses on software deployment and DataOps on data pipelines, MLOps bridges code, data, and models. It ensures machine learning workflows are reliable, automated, and production-ready.
Not every model requires full MLOps. It’s most beneficial when deploying models in production, especially if they need continuous monitoring, retraining, or scaling across teams or applications.
Yes. MLOps can be implemented on cloud platforms such as Google Vertex AI, Azure Machine Learning, or AWS SageMaker, as well as on-premises environments, depending on compliance, infrastructure, and scalability needs.
Popular tools include MLflow, Weights & Biases, Kubeflow, Airflow, Seldon, TensorFlow Serving, Prometheus, Grafana, and integrated platforms like AWS SageMaker, Google Vertex AI, and Azure ML. Each serves specific stages of the MLOps lifecycle.

Alexandra Mendes is a Senior Growth Specialist at Imaginary Cloud with 3+ years of experience writing about software development, AI, and digital transformation. After completing a frontend development course, Alexandra picked up some hands-on coding skills and now works closely with technical teams. Passionate about how new technologies shape business and society, Alexandra enjoys turning complex topics into clear, helpful content for decision-makers.
People who read this post, also found these interesting:







.webp)