
Les MLOps (Machine Learning Operations) sont un ensemble de pratiques qui permet aux organisations de déployer, de gérer et de faire évoluer des modèles d'apprentissage automatique en production. Il relie la science des données à l'ingénierie en ajoutant l'automatisation, la surveillance et la gouvernance tout au long du cycle de vie de l'apprentissage automatique.
À mesure que l'apprentissage automatique intègre les systèmes d'IA de production, les équipes sont confrontées à des défis tels que la dérive des modèles, le manque de fiabilité des déploiements et la lenteur des itérations. MLOps répond à ces problèmes grâce à une architecture, des outils et des meilleures pratiques bien définis qui rendent l'apprentissage automatique fiable et maintenable à grande échelle.
MLOps (opérations d'apprentissage automatique) est un ensemble de pratiques qui standardise et automatise le développement, le déploiement, la surveillance et la maintenance des modèles d'apprentissage automatique en production. Son objectif est de rendre les systèmes d'apprentissage automatique fiables, évolutifs et reproductibles, de la même manière que DevOps le fait pour les logiciels traditionnels, tout en tenant compte des défis uniques liés aux données et aux modèles.
À la base, MLOps se situe à l'intersection de l'apprentissage automatique, du génie logiciel et des opérations. Il couvre le cycle de vie complet de l'apprentissage automatique, de l'ingestion des données et de la formation des modèles au déploiement, à la surveillance et à l'amélioration continue. Contrairement aux logiciels traditionnels, les systèmes d'apprentissage automatique dépendent non seulement du code, mais également des données, des fonctionnalités et des paramètres du modèle, qui peuvent tous évoluer au fil du temps et affecter les performances.
Les MLOps sont apparus lorsque les organisations ont réalisé que la formation d'un modèle ne représentait qu'une petite partie de la création de valeur grâce à l'IA. Dans les environnements réels, les modèles doivent être versionnés, testés, déployés en toute sécurité, surveillés pour détecter des problèmes tels que la dérive des modèles et réentraînés à mesure que les données évoluent. Sans MLOps, les équipes sont souvent confrontées à des déploiements manuels, à des résultats incohérents et à des modèles qui se dégradent silencieusement en production.
Les principaux organismes de recherche et de cloud définissent les MLOps en des termes similaires :
Dans la pratique, MLOps permet aux équipes de passer des ordinateurs portables expérimentaux à des systèmes d'IA de production fiables, audités et améliorés au fil du temps, ce qui en fait une fonctionnalité fondamentale pour toute organisation qui souhaite sérieusement utiliser l'apprentissage automatique dans ses produits et services réels.
Le MLOps est important car de nombreuses initiatives d'apprentissage automatique bloquent ou échouent lors du déploiement en raison de flux de travail fragmentés et d'un manque de discipline opérationnelle, un problème bien documenté dans les analyses du secteur. Une approche MLOps structurée permet d'aligner les équipes et les technologies, réduisant ainsi les délais de production et les risques liés à la maintenance continue. Des organisations dotées de cadres opérationnels clairs bénéficient souvent d'une adoption et d'un retour sur investissement beaucoup plus rapides.
En outre, MLOps accélère le retour sur investissement des initiatives d'apprentissage automatique. UNE Conseil technologique de Forbes L'analyse indique que le chaos opérationnel du machine learning, tel que la lenteur des cycles de déploiement et le manque de clarté quant à la propriété des modèles, retarde considérablement la mise en production, renforçant ainsi le besoin de cadres opérationnels dédiés.
En bref, MLOps est ce qui rend l'IA de production durable. Il permet aux équipes d'avancer plus rapidement sans sacrifier la fiabilité, garantit la précision des modèles dans le temps et fournit les contrôles nécessaires pour faire fonctionner les systèmes d'apprentissage automatique en toute confiance à grande échelle.
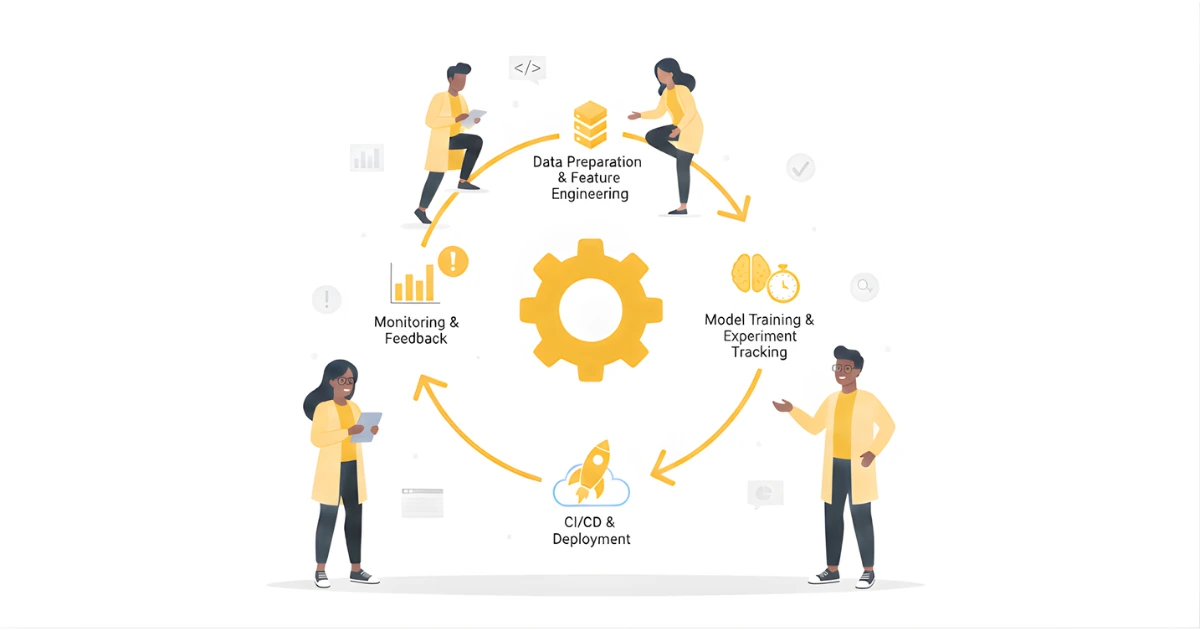
MLOps fonctionne en gérant l'ensemble cycle de vie de l'apprentissage automatique, de la collecte des données au déploiement en production et à l'amélioration continue. En appliquant des processus structurés et en automatisant, MLOps garantit la fiabilité, la reproductibilité et l'évolutivité des modèles. Le cycle de vie peut être résumé en six étapes clés :
L'apprentissage automatique commence par les données. Les pipelines MLOps collectent des données provenant de sources multiples, les valident et les stockent dans un format adapté à la formation. Les pipelines automatisés contribuent à garantir la qualité et la cohérence des données, en réduisant les erreurs avant qu'elles n'affectent les modèles.
Les données brutes sont transformées en fonctionnalités dont les modèles peuvent tirer des enseignements. MLOps garantit que les pipelines de fonctionnalités sont versionnés, reproductibles et surveillés, afin que les mêmes transformations puissent être appliquées de manière cohérente lors de la formation et de la production.
Les data scientists entraînent des modèles à l'aide de divers algorithmes et hyperparamètres. MLOps intègre le suivi des expériences, la gestion des versions des modèles et des tests automatisés pour comparer les performances et maintenir la reproductibilité. Des outils tels que MLflow et Weights & Biases sont couramment utilisés pour cette étape.
Avant le déploiement, les modèles sont validés par rapport à des données invisibles afin de mesurer la précision, l'équité et la fiabilité. Les pipelines MLOps incluent des tests automatisés et des contrôles de performance pour éviter toute régression ou biais dans les modèles de production.
Les modèles sont déployés en production à l'aide d'outils automatisés CI/CD oléoducs. Cela garantit un déploiement reproductible, sûr et rapide dans tous les environnements. Les stratégies de déploiement peuvent inclure des tests A/B, des versions Canary ou des mises à jour continues pour minimiser les risques.
Après le déploiement, les modèles sont surveillés pour détecter la dérive des performances, la dérive des données et les erreurs. MLOps permet un réentraînement automatique ou des alertes lorsque les métriques se dégradent. Les pratiques de gouvernance garantissent la conformité, la journalisation et l'audit des systèmes de machine learning de production.
Le besoin d'automatisation et de cohérence des flux de travail opérationnels se retrouve dans les analyses du secteur, qui soulignent que des processus et un outillage standardisés réduisent la friction entre expérimentation et production.
En résumé, MLOps automatise et normalise chaque étape du cycle de vie de l'apprentissage automatique, rendant les modèles fiables, évolutifs et maintenables en production.

Une architecture MLOps est un cadre structuré qui prend en charge le cycle de vie de bout en bout de l'apprentissage automatique, de l'ingestion des données au déploiement et à la surveillance. Il définit la manière dont les équipes organisent les outils, les pipelines et l'infrastructure pour fournir des systèmes d'IA de production fiables, évolutifs et maintenables.
Une architecture MLOps typique comprend les composants principaux suivants :
1. Couche de données
2. Modèle de couche d'entraînement
3. Registre des modèles et gestion des versions
4. Couche de déploiement
5. Couche de surveillance et d'observabilité
6. Niveau de gouvernance et de sécurité
En résumé, une architecture MLOps organise toutes les couches du cycle de vie de l'apprentissage automatique, des données, de la formation, du déploiement, de la surveillance et de la gouvernance, afin que les modèles puissent être déployés en toute sécurité et gérés efficacement à grande échelle.
MLOps s'appuie sur une gamme d'outils spécialisés pour automatiser, surveiller et gérer apprentissage automatique cycle de vie. Ces outils sont généralement regroupés par fonction, ce qui permet aux équipes de rationaliser les flux de travail, d'améliorer la reproductibilité et de faire évoluer les systèmes d'IA de production.
1. Suivi des expériences et gestion des versions des modèles
2. Orchestration et automatisation des pipelines
3. Déploiement et mise en service de modèles
4. Surveillance et observabilité
5. Plateformes cloud pour les MLOP de bout en bout
En conclusion, les outils MLOps sont organisés autour de plateformes d'expérimentation, d'orchestration, de déploiement, de surveillance et de cloud, permettant aux équipes de fournir des modèles d'apprentissage automatique fiables et évolutifs en production.
La mise en œuvre efficace des MLOps nécessite l'adoption de pratiques qui rendent les systèmes d'apprentissage automatique fiables, maintenables et évolutifs. Le respect des meilleures pratiques du secteur garantit que les modèles restent précis, que les déploiements sont prévisibles et que les équipes peuvent itérer plus rapidement.
McKinsey note que le fait de se concentrer sur la qualité des données, la gouvernance, l'intégration CI/CD et l'automatisation améliore considérablement les performances des systèmes d'IA en production.
1. Automatisez les flux de travail
2. Version : Tout
3. Surveillez les modèles en continu
4. Conception axée sur la reconversion et l'amélioration continue
5. Intégrez rapidement la gouvernance et la conformité
6. Alignez les équipes autour de la propriété partagée
En suivant les meilleures pratiques MLOps, l'automatisation, la gestion des versions, la surveillance, la reconversion, la gouvernance et l'alignement des équipes garantissent que les systèmes d'apprentissage automatique restent précis, évolutifs et fiables en production.
Les MLOps, DevOps et DataOps sont des pratiques connexes qui améliorent l'efficacité opérationnelle, mais elles se concentrent sur différents aspects des flux de travail logiciels et de données. Comprendre leurs différences aide les équipes à mettre en œuvre les MLOP de manière efficace et sans confusion.
| Practice | Focus | Key Activities | Primary Goal |
|---|---|---|---|
| DevOps | Software development & deployment | CI/CD, infrastructure automation, monitoring, testing | Deliver reliable, scalable software faster |
| DataOps | Data pipelines & quality | Data ingestion, transformation, validation, governance | Ensure accurate, clean, and timely data delivery |
| MLOps | Machine learning systems | Model training, versioning, deployment, monitoring, retraining, governance | Deliver reliable, scalable, and maintainable production AI systems |
Principales différences :
En résumé, MLOps complète DevOps et DataOps en comblant le fossé entre les logiciels, les données et les modèles, garantissant ainsi des flux de travail d'apprentissage automatique robustes, évolutifs et prêts pour la production.
Même avec les bons outils, de nombreuses organisations ont du mal à mettre en œuvre les MLOP en raison des silos opérationnels, des barrières culturelles et de la prolifération des outils.
Les propres recherches d'Imaginary Cloud sur les défis de l'adoption de l'IA a constaté que l'adhésion de l'organisation et l'alignement stratégique constituent souvent des obstacles plus importants que des problèmes purement techniques, soulignant ainsi l'importance d'aligner les MLOP sur les objectifs généraux de l'entreprise.
1. Silos organisationnels
2. Excentration des outils et complexité de l'intégration
3. Problèmes de qualité et de disponibilité des données
4. Les obstacles liés à la culture et aux compétences
5. Défis en matière de surveillance et de gouvernance
En résumé, les équipes qui adoptent les MLOP sont confrontées à des défis organisationnels, techniques et culturels, notamment les silos, la complexité des outils, les problèmes de qualité des données et les exigences de gouvernance. La planification précoce de ces obstacles améliore l'adoption et garantit la fiabilité de l'IA de production.
MLOps est essentiel pour transformer les expériences d'apprentissage automatique en systèmes d'IA de production fiables et évolutifs. En combinant une architecture structurée, les bons outils et les meilleures pratiques, les équipes peuvent surmonter des défis tels que la dérive des modèles, les problèmes de qualité des données et la complexité du déploiement.
Que vous commenciez tout juste votre parcours MLOps ou que vous cherchiez à optimiser les flux de travail existants, l'adoption de ces principes garantit la précision, la maintenance et l'impact de vos modèles au fil du temps.
Êtes-vous prêt à mettre en production votre machine learning en toute confiance ? Contactez notre équipe d'experts MLOps dès aujourd'hui et découvrez comment nous pouvons vous aider à rationaliser vos opérations d'IA.

MLOps résout les problèmes liés à l'IA de production, notamment les déploiements peu fiables, la dérive des modèles, la mauvaise qualité des données et la lenteur des cycles d'itération. Il garantit que les modèles d'apprentissage automatique sont reproductibles, évolutifs et maintenables.
Alors que DevOps se concentre sur le déploiement de logiciels et que le DataOps se concentre sur les pipelines de données, le MLOps fait le pont entre le code, les données et les modèles. Il garantit que les flux de travail d'apprentissage automatique sont fiables, automatisés et prêts pour la production.
Tous les modèles ne nécessitent pas un MLOP complet. C'est particulièrement utile lors du déploiement de modèles en production, en particulier s'ils nécessitent une surveillance continue, une formation ou une évolutivité entre les équipes ou les applications.
Oui Les MLOps peuvent être implémentés sur des plateformes cloud telles que Google Vertex AI, Azure Machine Learning ou AWS SageMaker, ainsi que dans des environnements sur site, en fonction des besoins de conformité, d'infrastructure et d'évolutivité.
Les outils les plus populaires incluent MLflow, Weights & Biases, Kubeflow, Airflow, Seldon, TensorFlow Serving, Prometheus, Grafana et des plateformes intégrées telles qu'AWS SageMaker, Google Vertex AI et Azure ML. Chacune dessert des étapes spécifiques du cycle de vie des MLOps.

Alexandra Mendes est spécialiste senior de la croissance chez Imaginary Cloud et possède plus de 3 ans d'expérience dans la rédaction de textes sur le développement de logiciels, l'IA et la transformation numérique. Après avoir suivi un cours de développement frontend, Alexandra a acquis des compétences pratiques en matière de codage et travaille désormais en étroite collaboration avec les équipes techniques. Passionnée par la façon dont les nouvelles technologies façonnent les entreprises et la société, Alexandra aime transformer des sujets complexes en contenus clairs et utiles pour les décideurs.
People who read this post, also found these interesting:







.webp)