

Azure Service Fabric is Microsoft’s platform for building and running stateful and stateless microservices with high density and built-in lifecycle management. For enterprises evaluating what Azure Service Fabric is and when to use it, the platform delivers reliable orchestration, fast start-up, and simplified operations via Service Fabric Managed Clusters (SFMC).
Key benefits:
For enterprise teams on Azure, Azure Service Fabric delivers reliable, high-density microservices with strong lifecycle control.
Why enterprises care:
Service Fabric provides distributed systems orchestration for stateful and stateless workloads, with lifecycle and health built in. It runs guest executables and containers, enabling high density and rapid start-up, beyond a Kubernetes-only container orchestration model.
Managed operations: SFMC simplifies provisioning, certificates, and governance.
Stateful microservices need availability, consistency, and speed without heavy custom plumbing. Service Fabric for enterprises adds the guardrails and automation to meet those needs on Azure.
Decide based on workload needs, not just platform fashion. Azure Service Fabric excels when you need stateful microservices, tight latency, and built-in lifecycle control; AKS shines for Kubernetes-native, portable container estates with a broad OSS toolchain.
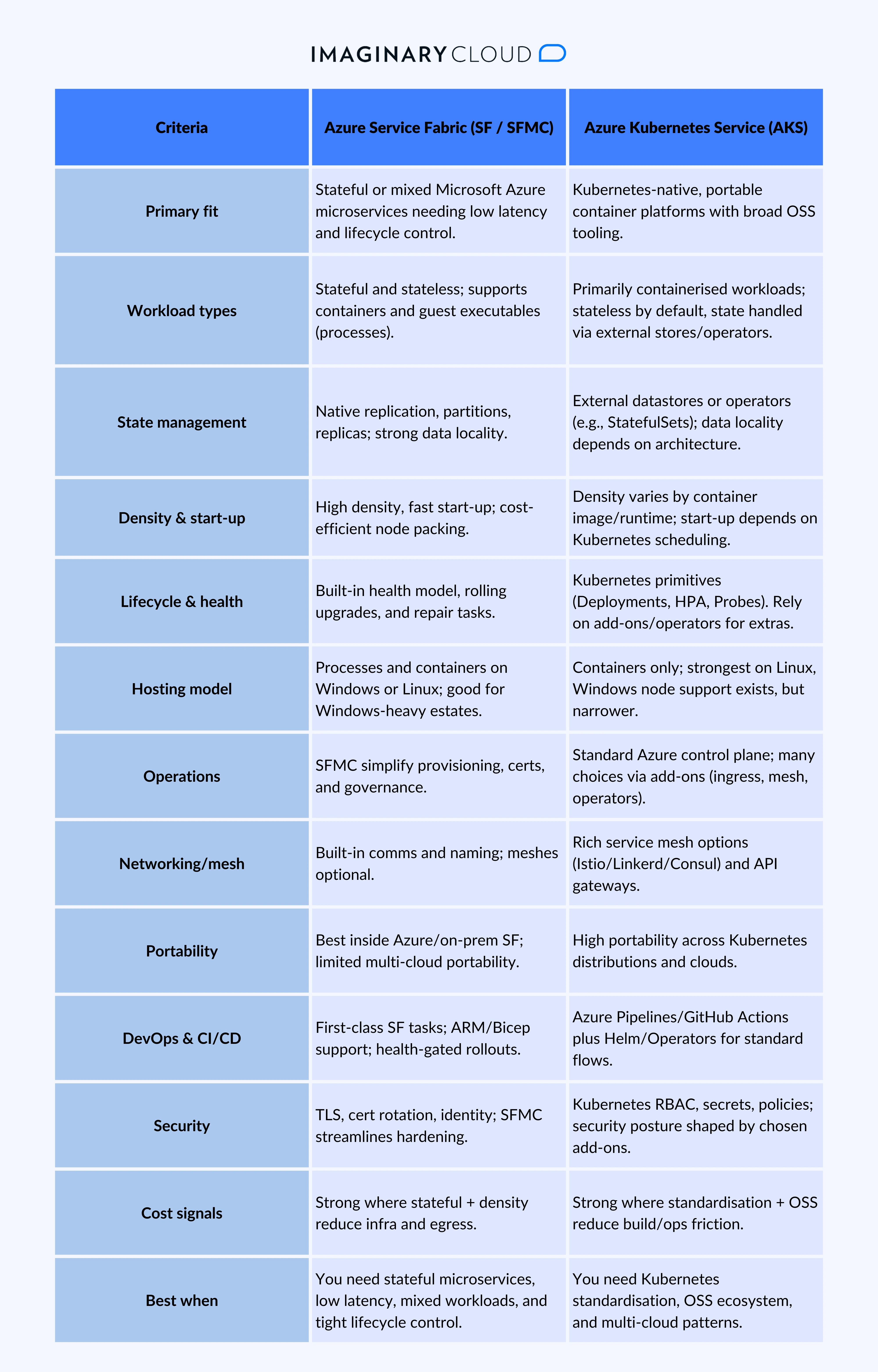
In summary: between Azure Service Fabric and AKS, choose Azure Service Fabric (and SFMC) for stateful, low-latency, high-density enterprise microservices and mixed hosting needs; choose AKS for Kubernetes-standard container estates, portability, and rich OSS integration.
Azure Service Fabric architecture groups services into a resilient, high-density cluster with built-in health, upgrades, and placement control. It supports stateful and stateless microservices, partitions work for scale, and replicates data for reliability, fitting enterprises that need predictable SLOs and low-latency access to state.
In summary: Azure Service Fabric uses partitions, replicas, and policy-driven placement to deliver scalability, reliability, and low-latency access to state, while SFMC reduces operational overhead for enterprise teams.
Service Fabric Managed Clusters are the managed way to run Azure Service Fabric. Microsoft manages the cluster’s supporting resources so teams can focus on deployment, lifecycle, and reliability rather than scaffolding. This is ideal for Service Fabric for enterprises that need speed, governance, and repeatability.
Why SFMC simplifies ops:
In summary: SFMC brings managed governance, security, and lifecycle control to Azure Service Fabric, reducing operational burden while improving reliability and time-to-value.
Azure Service Fabric (including Service Fabric Managed Clusters) is designed for enterprise-grade microservices that must scale predictably, stay available, and ship updates safely. It blends partitioning, replication, and health-driven rollouts to meet SLOs while keeping operations simple for Service Fabric for enterprises.
In summary: Azure Service Fabric achieves scalability, reliability, and controlled lifecycle through partitioning, replication, health signals, and automated rollouts, giving enterprises predictable performance with lower operational overhead.
Azure Service Fabric supports enterprise-grade controls for Microsoft Azure microservices that must meet strict compliance. It enforces encryption in transit, tight identity and access control, and governed operations, ideal for Service Fabric for enterprises in finance, healthcare, or the public sector.
In summary: Azure Service Fabric provides encryption, identity, network isolation, and policy-driven governance, backed by SFMC to simplify certificate management and audits, so regulated enterprises can meet security requirements without slowing delivery.
Azure Service Fabric suits mission-critical, always-on systems. It powers stateful and stateless Microsoft Azure microservices that need low latency, high density, and safe lifecycle control, making it an ideal Service Fabric for enterprises.
In summary: choose Azure Service Fabric when applications need stateful microservices, predictable latency, and safe upgrades at scale, standard requirements across finance, telecoms, retail, healthcare, and IoT.
Yes. Azure Service Fabric runs microservices that call Azure AI Services, Azure OpenAI, and Azure Machine Learning endpoints, and it connects cleanly to Microsoft Fabric/OneLake, Azure Data Lake, Event Hubs, and Azure SQL. This suits Service Fabric for enterprises that need low-latency inference, governed data, and safe rollouts.
In summary: Azure Service Fabric integrates natively with Azure AI/ML and Microsoft Fabric data services, combining secure connectivity, governed MLOps, and low-latency service patterns that enterprises need for production AI.

Azure Service Fabric deployment is a clear path: build locally, automate CI/CD, then promote to Service Fabric Managed Clusters (SFMC) with health-gated rollouts. Keep everything as code (manifests + ARM/Bicep) and use Azure DevOps or GitHub Actions for repeatable releases.
Tip: keep a single, parameterised pipeline that targets dev, staging, and prod; switch only environment variables, secrets, and capacity.
In summary: standardise your Azure Service Fabric deployment with manifests, ARM/Bicep, and CI/CD; promote through SFMC with health-gated rollouts, and run to SLOs with SFX, Application Insights, and Log Analytics.
Moving from Cloud Services (Extended Support) to Azure Service Fabric (SFMC) is a structured modernisation. Keep the path simple: map roles to services, standardise deployment, and protect users with staged rollouts. This suits Service Fabric for enterprises that need safer change with tight SLOs.
Risk controls to apply
In summary: keep migration pragmatic and reversible: map roles to services, standardise Service Fabric deployment with CI/CD and IaC, and use SFMC plus health-gated releases to protect uptime while you modernise.
Evaluate Azure Service Fabric with a short, testable checklist so you can confirm fit for enterprise-grade microservices, stateful workloads, and SFMC operations before scaling.
In summary: validate Azure Service Fabric architecture, benefits, scalability, reliability, and deployment flow in a small, production-like pilot, measuring density, latency, and change safety before broader rollout.
Azure Service Fabric is a strong fit when you need stateful microservices, high density, and health-gated releases, with SFMC to cut operational toil. If that matches your roadmap, move from research to a pilot and prove it against your SLOs.
Kick-off now: Book an AI Readiness Assessment to validate fit, confirm architecture, and scope a production-like pilot tailored to your workloads.
Azure Service Fabric is used to build and run stateful and stateless microservices that need low latency, high density, and built-in lifecycle management on Azure. Typical uses include:
Different product. Microsoft Fabric is a unified analytics platform (Power BI, Data Factory, Data Engineering, Real-Time Intelligence, Data Warehouse, OneLake). Common uses:
Note: Azure Service Fabric (microservices/app platform) ≠ Microsoft Fabric (analytics platform).
No. Azure Service Fabric supports stateful services and runs processes and containers with health-driven upgrades built in. Kubernetes (AKS) is a container orchestration platform focused on portability and a broad OSS ecosystem.
If you mean Azure Service Fabric, it includes: clusters, node types, partitions and replicas, a built-in health and upgrade model, naming/communication services, Service Fabric Explorer, and Service Fabric Managed Clusters (SFMC) for managed operations. These deliver scalability, reliability, secure communications, and simpler day-2 operations.
Yes. Azure Service Fabric powers enterprise-grade microservices, including stateful apps, and remains supported on Azure, with Service Fabric Managed Clusters (SFMC) simplifying operations.
Windows and Linux. Run containers and guest executables side by side, useful for Windows-heavy or mixed estates.
Authenticate, then use Service Fabric Explorer, Azure CLI/PowerShell, or pipelines. Manage certificates, scale node types, and perform rolling upgrades with health gates.
Build stateless or stateful services. Use .NET, Java, and containerised stacks. Expose HTTP/gRPC endpoints and use platform naming/communication APIs where needed.
Yes. Use TLS, certificate rotation, managed identities, private networking, and Azure Policy. SFMC streamlines hardening and audit readiness.
Yes. Many teams begin with stateless services on containers, then introduce stateful services for low-latency paths as needs evolve.


Alexandra Mendes is a Senior Growth Specialist at Imaginary Cloud with 3+ years of experience writing about software development, AI, and digital transformation. After completing a frontend development course, Alexandra picked up some hands-on coding skills and now works closely with technical teams. Passionate about how new technologies shape business and society, Alexandra enjoys turning complex topics into clear, helpful content for decision-makers.
People who read this post, also found these interesting:






-%2520Survey%2520Insights.webp)
