
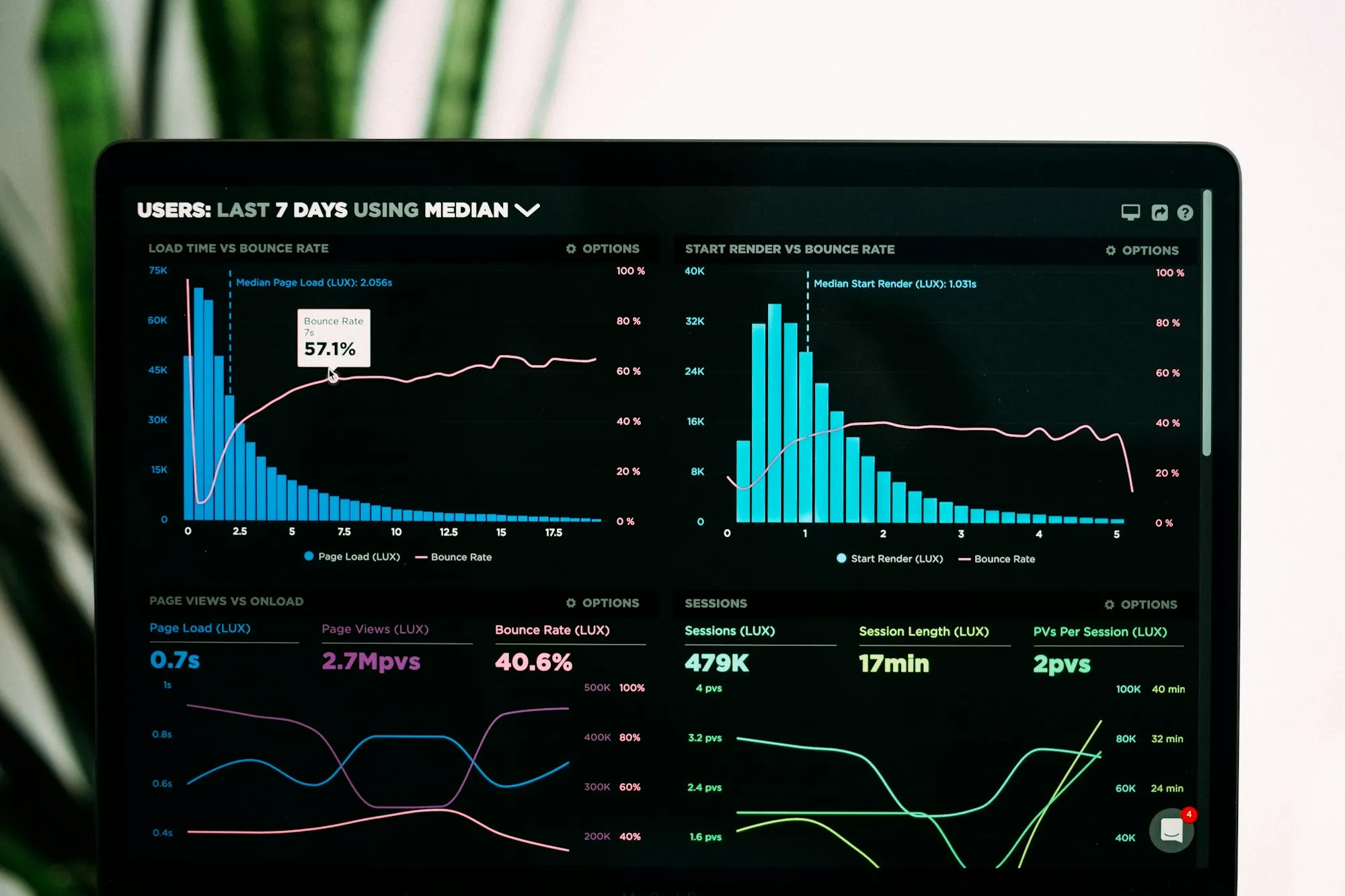
Data mining er en verden i sig selv, hvorfor det let kan blive meget forvirrende. Der er et utroligt antal Data Mining værktøjer tilgængelig på markedet. Mens nogle måske er mere velegnede til håndtering af data mining i Big Data, skiller andre sig ud for deres datavisualiseringsfunktioner.
Som forklaret i denne artikel handler data mining om at opdage mønstre i data og forudsige tendenser og adfærd. Kort sagt, det er processen med at konvertere store datasæt til relevant information. Der er ikke meget brug for at have enorme mængder data, hvis vi faktisk ikke ved, hvad det betyder.
Denne proces omfatter andre områder såsom maskinindlæring, databasesystemer, og statistik. Derudover kan data mining-funktioner variere meget fra datarensning til kunstig intelligens, dataanalyse, regression, klyngedannelse osv. Derfor udvikles og opdateres mange værktøjer til at udføre disse funktioner og sikre Kvaliteten af store datasæt (da dårlig datakvalitet resulterer i dårlig og irrelevant indsigt). Denne artikel søger at forklare de bedste muligheder for hver funktion og kontekst. Fortsæt med at læse for at finde ud af vores 21 bedste mineværktøjer!
Data mining er en proces, der omfatter statistik, kunstig intelligens og maskinlæring. Ved at bruge intelligente metoder udtrækker denne proces information fra data, hvilket gør den omfattende og fortolkbar. Processen med data mining gør det muligt at opdage mønstre og relationer inden for datasæt samt forudsige tendenser og adfærd.
Teknologiske fremskridt har bidraget til hurtigere og lettere automatiseret dataanalyse. Jo større og mere komplekse datasættene er, jo større er chancerne for at finde relevant indsigt. Ved at identificere og forstå meningsfulde data kan organisationer gøre god brug af værdifuld information til at træffe beslutninger og nå de foreslåede mål.
Data mining kan anvendes til flere formål, såsom markedssegmentering, trendanalyse, afsløring af svig, databasemarkedsføring, kreditrisikostyring, uddannelse, finansiel analyse osv. Processen med datamining kan opdeles i flere trin i henhold til hver organisations tilgang, men generelt inkluderer den følgende fem trin:
Data warehouse er processen med at indsamle og administrere data. Det gemmer data fra forskellige kilder i et lager og er især fordelagtig for operationelle forretningssystemer (f.eks. CRM-systemer). Denne proces sker før data mining, da denne vil opdage datamønstre og relevant information fra de lagrede data.
Fordelene ved datavarehuset omfatter: forbedring af datakvaliteten i kildesystemer; beskyttelse af data mod kildesystemets opdateringer; evnen til at integrere flere datakilder; og dataoptimering.
Som tidligere nævnt er data mining en yderst nyttig og gavnlig proces, der kan hjælpe organisationer med at udvikle sig strategier baseret på relevant dataindsigt. Data mining krydser mange brancher (såsom forsikring, bank, uddannelse, medier, teknologi, fremstilling osv.) og er kernen i analytisk indsats.
Processen med data mining kan bestå af forskellige teknikker. Blandt de mest udbredte er regressionsanalyse (forudsigelig), opdagelse af associeringsregel (beskrivende) klynger (beskrivende), og klassificering (forudsigelig). Det kan være fordelagtigt at have yderligere viden om forskellige data mining-værktøjer, når man udvikler en analyse. Husk dog, at disse værktøjer har forskellige måder at fungere på på grund af de forskellige algoritmer, der anvendes i deres design.
Den voksende betydning af data mining inden for en række områder resulterede i kontinuerlig introduktion af nye værktøjer og softwareopgraderinger til markedet. Derfor bliver det en tvivlsom og kompleks opgave at vælge den rigtige software. Så inden du træffer nogen forhastede beslutninger, er det afgørende at overveje forretnings- eller forskningskravene.
Denne artikel samlede top 21 data mining værktøjer, som er segmenteret efter syv kategorier:
Husk, at nogle af disse værktøjer muligvis hører til mere end en kategori. Vores valg blev foretaget i henhold til den kategori, hvor hvert værktøj skiller sig mest ud. For eksempel, selvom Amazon EMR hører til cloud-baserede løsninger, er det samtidig et godt værktøj til at håndtere Big Data. Inden vi går videre til de faktiske værktøjer, benytter vi også lejligheden til kort at forklare forskellen mellem de to mest populære programmeringssprog til datavidenskab: R og Python. Selvom begge sprog er velegnede til de fleste datavidenskabsopgaver, kan det være svært (især i starten) at vide, hvordan man vælger mellem begge.
Python og R er blandt de mest anvendte programmeringssprog til datavidenskab. Den ene er ikke nødvendigvis bedre end den anden, da begge muligheder har deres styrker og svagheder. På den ene side R blev udviklet med statistisk analyse i tankerne; på den anden side Python tilbyder en mere generisk tilgang til datavidenskab. Yderligere er R mere fokuseret på dataanalyse og er mere fleksibel til at bruge tilgængelige biblioteker. Tværtimod er Pythons primære mål implementering og produktion, og det giver mulighed for at oprette modeller fra bunden. Sidst men ikke mindst er R ofte integreret til at køre lokalt, og Python er integreret med apps. På trods af deres forskelle kan begge sprog håndtere store mængder data og have en bred stak biblioteker.
SPSS, SAS, Oracle Data Mining og R er data mining-værktøjer med et overvejende fokus på den statistiske side snarere end den mere generelle tilgang til data mining, som Python (for eksempel) følger. I modsætning til de andre statistiske programmer er R imidlertid ikke en kommerciel integreret løsning. I stedet er det open source.
1. IBM SPSSSPSS er en af de mest populære statistiske softwareplatforme. SPSS stod tidligere for Statistical Package for the Social Sciences, som angiver dets oprindelige marked (områderne sociologi, psykologi, geografi, økonomi osv.). IBM købte imidlertid softwaren i 2009, og senere, i 2015, begyndte SPSS at stå for Statistical Product and Service Solutions. Softwarens avancerede evner giver et bredt bibliotek med maskinlæringsalgoritmer, statistisk analyse (beskrivende, regression, klyngedannelse osv.), tekstanalyse, integration med big data osv. Desuden giver SPPS brugeren mulighed for at forbedre deres SPSS Syntax med Python og R ved hjælp af specialiserede udvidelser.
2. RR er en programmeringssprog og et miljø til statistisk beregning og grafik. Det er kompatibelt med UNIX-platforme, FreeBSD, Linux, macOS og Windows-operativsystemer. Dette gratis software kan køre en række statistiske analyser, såsom tidsserieanalyse, klyngedannelse og lineær og ikke-lineær modellering. Desuden defineres den også som en miljø til statistisk beregning da det er designet til at give et sammenhængende system, der leverer fremragende data mining-pakker. Samlet set, R er et fantastisk og meget komplet værktøj, der desuden tilbyder grafiske faciliteter til dataanalyse og en omfattende samling af mellemliggende værktøjer. Det er en open source-løsning til statistisk software som SAS og IBM SPSS.
3. SASSAS står for Statistical Analysis System. Dette værktøj er en glimrende mulighed for tex minedrift, optimering og datamining. Det tilbyder adskillige metoder og teknikker til at opfylde flere analytiske evner, der vurderer organisationens behov og mål. Det inkluderer beskrivende modellering (nyttig til at kategorisere og profilere kunder), forudsigelig modellering (praktisk til at forudsige ukendte resultater) og præskriptiv modellering (nyttig til at analysere, filtrere og transformere ustrukturerede data - såsom e-mails - kommentarfelter, bøger osv.). Desuden er den distribueret hukommelsesbehandlingsarkitektur Det gør det også meget skalerbart.
4. Oracle-dataminingOracle Data Mining (ODB) er en del af Oracle Advanced Analytics. Dette dataminingsværktøj giver ekstraordinære dataforudsigelsesalgoritmer til klassificering, regression, klyngedannelse, tilknytning, attributbetydning og anden specialiseret analyse. Disse kvaliteter tillader ODB for at hente værdifuld dataindsigt og nøjagtige forudsigelser. Desuden omfatter Oracle Data Mining programmatiske grænseflader til SQL, PL/SQL, R og Java.
5. KNIMEKNIME står for Konstanz Information Miner. Softwaren følger en open source-filosofi og blev først udgivet i 2006. I de senere år er det ofte blevet betragtet som en førende software til datavidenskab og maskinlæring platforme, der bruges i mange brancher såsom banker, biovidenskab, udgivere og konsulentfirmaer. Desuden tilbyder det både on-premise og på sky stik, hvilket letter flytning af data mellem miljøer. Selvom KNIME er implementeret i Java, softwaren leverer også noder, så brugerne kan køre den i Ruby, Python og R.
6. Rapid MinerHurtig minearbejder er et open source-dataminingsværktøj med problemfri integration med både R og Python. Det giver avanceret analyse ved at tilbyde adskillige produkter til at skabe nye data mining-processer. Plus, det har et af de bedste forudsigelige analysesystemer. Denne open source er skrevet i Java og kan integreres med WEKA og R-tool. Nogle af de mest værdifulde funktioner inkluderer: fjernanalysebehandling; oprette og validere forudsigelige modeller; flere tilgængelige datastyringsmetoder; indbyggede skabeloner og gentagelige arbejdsgange; datafiltrering, sammenlægning og sammenføjning.
7. orangeorange er en python-baseret software til datamining med åben kildekode. Det er et godt værktøj for dem, der starter med data mining, men også for eksperter. Ud over sine data mining-funktioner understøtter orange også maskinindlæringsalgoritmer til datamodellering, regression, klyngedannelse, forbehandling og så videre. Desuden giver orange et visuelt programmeringsmiljø og muligheden for at trække og slippe widgets og links.
Big data refererer til en massiv mængde data, som kan være struktureret, ustruktureret eller semistruktureret. Det dækker de fem V-egenskaber: volumen, variation, hastighed, ægthed og værdi. Big Data involverer normalt flere terabyte eller petabyte data. På grund af dens kompleksitet kan det være svært (for ikke at sige umuligt) at behandle data på en enkelt computer. Således kan den rigtige software og datalagring være yderst nyttig til at opdage mønstre og forudsige tendenser. Hvad angår data mining-løsninger til big data, er disse vores bedste valg:
8. Apache SparkApache Spark skiller sig ud for sin brugervenlighed ved håndtering af big data og er et af de mest populære værktøjer. Det har flere grænseflader tilgængelige i Java, Python (PySpark), R (SparkR), SQL, Scala og tilbud over 80 højtstående operatører, hvilket gør det muligt at skrive kode hurtigere. Plus, dette værktøj suppleres af flere biblioteker, såsom SQL og DataFrames, Spark Streaming, GRPAHx og MLlib. Apache Spark tiltrækker også opmærksomhed for sin beundringsværdige ydeevne, hvilket giver en hurtig databehandling og datastrømming platformen.

9. Hadoop MapReduceHadoop er en samling af open source-værktøjer, der håndterer store mængder data og andre beregningsproblemer. Selvom Hadoop er skrevet i Java, ethvert programmeringssprog kan bruges med Hadoop Streaming. MapReduce er en Hadoop implementering og en programmeringsmodel. Det har været en bredt vedtaget løsning til udførelse af komplekse datamining på Big Data. Kort sagt giver det brugerne mulighed for at kortlægge og reducere funktioner, der normalt bruges i funktionel programmering. Dette værktøj kan udføre store sammenføjningsoperationer på tværs af enorme datasæt. Desuden tilbyder Hadoop forskellige applikationer såsom brugeraktivitetsanalyse, ustruktureret databehandling, loganalyse, tekstminedrift osv.
10. QlikQlik er en platform, der adresserer analyse og data mining gennem en skalerbar og fleksibel tilgang. Det har en brugervenlig træk-og-slip-grænseflade og reagerer øjeblikkeligt på ændringer og interaktioner. Derudover understøtter Qlik flere datakilder og problemfri integration med forskellige applikationsformater enten via stik og udvidelser, indbygget app eller sæt API'er. Det er også et godt værktøj til at dele relevant analyse ved hjælp af et centraliseret hub.
11. Scikit-lærScikit-lær er et gratis softwareværktøj til maskinlæring i Python, giver fremragende dataminingfunktioner og dataanalyse. Det tilbyder et stort antal funktioner såsom klassificering, regression, klyngedannelse, forbehandling, modelvalg og dimensionsreduktion.
12. Srangle (R)skrangle blev udviklet i R programmeringssprog og er kompatibel med macOS-, Windows- og Linux-operativsystemer. Det bruges hovedsageligt til kommercielle virksomheder og virksomheder, såvel som for lærd formål (især i USA og Australien). Beregningskraften i R gør det muligt for denne software at levere funktioner som klynger, datavisualisering, modellering og anden statistisk analyse.
13. Pandaer (Python)Til datamining i Python Pandaer er også et almindeligt kendt open source-værktøj. Det er et bibliotek, der skiller sig ud for at arbejde med dataanalyse og styring datastrukturer.
14. H3OH3O er en open source data mining software, der hovedsageligt bruges af organisationer til at analysere data, der er gemt i Cloud-infrastruktur. Dette værktøj er skrevet i R Sprog, men er også kompatibel med Python til bygningsmodeller. En af de største fordele er, at H3O tillader en hurtig og nem implementering i produktion på grund af Javas sprogunderstøttelse.
Cloud-baserede løsninger bliver stadig mere nødvendige for data mining. Implementeringen af data mining teknikker gennem skyen giver brugerne mulighed for at hente vigtig information fra praktisk talt integrerede datalager, hvilket reducerer omkostningerne ved opbevaring og infrastruktur.
15. Amazon EMRAmazon EMR er en cloud-løsning til behandling af store mængder data. Brugere bruger dette værktøj ikke kun til datamining men også til at udføre andre datavidenskabelige opgaver såsom webindeksering, logfilanalyse, økonomisk analyse, maskinlæring osv. Denne platform bruger en række forskellige open source-løsninger (f.eks. Apache Spark og Apache Flink) og letter skalerbarhed i store datamiljøer ved at automatisere opgaver (for eksempel tuning af klynger).
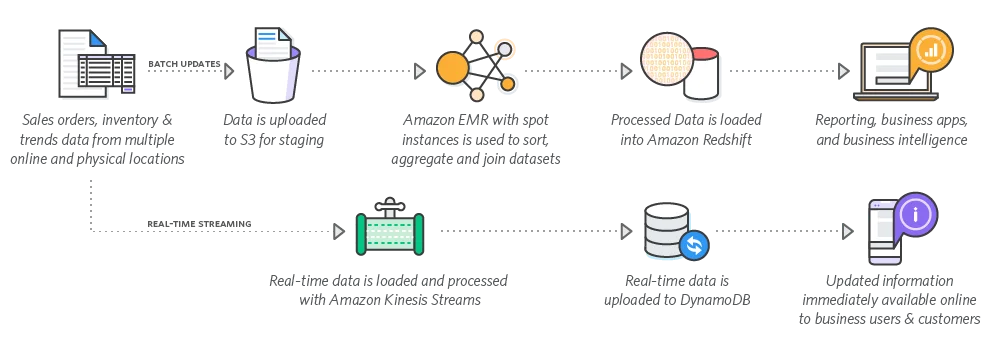
16. Azure MLAzure ML er et skybaseret miljø skabt til bygning, øvelser og implementering af maskinlæringsmodeller. Til datamining kan Azure ML udføre prædiktiv analyse og give brugerne mulighed for at beregne og manipulere datamængder fra cloudplatformen.
17. Google AI-platformPå samme måde som Amazon EMR og Azure ML, Google AI-platform Den er også cloud-baseret. Denne platform giver en af største maskinlæringsstakke. Google AI Platform indeholder flere databaser, maskinlæringsbiblioteker og andre værktøjer, som brugerne kan bruge i skyen til at udføre data mining og andre datavidenskabsfunktioner.
Neurale netværk består i at assimilere data på den måde, menneskelig hjerne behandler information. Med andre ord har vores hjerne millioner af celler (neuroner), der behandler ekstern information og bagefter producerer et output. Neurale netværk følger det samme princip og kan bruges til datamining ved at omdanne rå data til relevant information.
18. PyTorchPytorch er en Python-pakke og en dyb læringsramme baseret på Torch-biblioteket. Det blev oprindeligt udviklet af Facebooks AI Research Lab (FAIR), og det er et meget velkendt værktøj inden for Data Science på grund af dets dybe neurale netværksfunktion. Det giver brugerne mulighed for at udføre data mining-trinene for at programmere en hele neurale netværk: indlæse data, forbehandle data, definere en model, træne den og evaluere. Plus, med en stærk GPU-acceleration, Torch muliggør en hurtig array-beregning. For nylig, i september 2020, blev dette bibliotek R. Lommelygten til R-økosystemet inkluderer fakkel, fakkelvision, torchaudio og andre udvidelser.
19. TensorFlowPå samme måde som PyTorch, TensorFlow er også et Python-bibliotek open source til maskinlæring, som Google Brain Team oprindeligt udviklede. Det kan bruges til at opbygge deep learning-modeller og har et højt fokus på dybe neurale netværk. Ud over en fleksibel økosystem af værktøjer, TensorFlow leverer også andre biblioteker og har en meget populær fællesskab hvor udviklere kan stille spørgsmål og dele. På trods af at det var et Python-bibliotek, introducerede TensorFlow i 2017 og R-grænseflade fra RStudio til TensorFlow API.
Datavisualisering er den grafiske repræsentation af de oplysninger, der er ekstraheret fra data mining-processen. Disse værktøjer giver brugerne mulighed for at få en visuel forståelse af dataindsigterne (tendenser, mønstre og afvigelser) gennem grafer, diagrammer, kort og andre visuelle elementer.
20. MatplotlibMatplotlib er et fremragende værktøj til datavisualisering i Python. Dette bibliotek giver mulighed for at bruge interaktive figurer og oprettelse af kvalitetsplot (for eksempel histogrammer, spredningsplot, 3D-plot og billedplot), der senere kan tilpasses (stilarter, akseegenskaber, skrifttype osv.).
21. ggplot2ggplot2 er et datavisualiseringsværktøj og et af de mest populære R-pakker. Dette værktøj giver brugerne mulighed for at ændre komponenter i et plot med et højt abstraktionsniveau. Desuden giver det brugerne mulighed for at opbygge næsten enhver type graf og forbedre grafikkens kvalitet såvel som æstetik.
For at vælge det mest passende værktøj er det først vigtigt at have forretnings- eller forskningsmålene veletablerede. Det er ret almindeligt, at udviklere eller dataforskere, der arbejder med data mining, lærer flere værktøjer. Dette kan være en udfordring, men også yderst nyttigt til at udtrække relevant dataindsigt.
Som sagt er de fleste data mining værktøjer afhængige af to primære programmeringssprog: R og Python. Hvert af disse sprog giver et komplet sæt pakker og respektive biblioteker til datamining og datavidenskab generelt. På trods af disse programmeringssprogs dominans er integrerede statistiske løsninger (som SAS og SPSS) stadig meget udbredt af organisationer.


Marketing praktikant med særlig interesse for teknologi og forskning. I min fritid spiller jeg volleyball og forkæler min hund så meget som muligt.

Data Scientist med en dyb passion for teknik, fysik, og matematik. Jeg kan godt lide at lytte til og lave musik, rejse, og ride mountainbike-stier.

Data Scientist, der elsker at tackle udfordrende problemer. I min fritid bager jeg, går lange gåture og læser om genomik og ernæring.
People who read this post, also found these interesting:





.webp)
.webp)
