

At the core of data science are math and statistics, which is a necessary background to understand and create advanced analytics. In fact, advanced analytics relies on statistics, as well as on operations research and computer programming. It comprises the systematic (autonomous or semi-autonomous) computational examination of data, aiming to identify and interpret significant patterns in data.
Currently, the tech industry is increasingly seeking more deep analytical expertise to discover models and patterns from large data sets. Besides data mining techniques, it is also vital to have a good understanding of algorithms, automation techniques, computing architectures, and so on.
This article focuses specifically on data mining techniques. We will introduce six essential math and statistic techniques: classification, association, tracking patterns, outlier detection, regression, and clustering.
Further, we will also describe how advanced analytics technologies contribute to data mining. In that sense, we will explain the following technologies: neural networks and deep learning, natural language processing, and dimensionality reduction.
According to SAS's report on "Advanced Analytics: Moving Toward AI, Machine Learning, and Natural Language Processing", technologies such as Machine Learning (ML), Artificial Intelligence (AI), and Natural Language Processing (NLP) already exist for decades. However, businesses only started exploring these advanced analytics technologies over the last years. The main benefits of these technologies rely on the ability to improve operational efficiencies, understand behaviors, and gain a competitive advantage.
Table of Contents
What is Data Mining?
Data Mining Techniques
➤ 1. Classification
➤ 2. Association
➤ 3. Tracking Patterns
➤ 4. Outlier detection
➤ 5. Regression
➤ 6. Clustering
Advanced Analytics and Data Mining
➤ Neural networks and deep learning
➤ Natural Language Processing (NLP)
➤ Dimensionality reduction
Conclusion
What is data mining?
Data mining is a process that embraces statistics, artificial intelligence (AI), and machine learning (ML). This process enables data scientists to identify patterns, as well as relationships, within data sets. Data mining techniques are advantageous to predict trends and behaviors, allowing businesses and organizations (e.g., political, academic, etc.) to make informed decisions.
By using intelligent methods, data mining techniques are able to retrieve information from data, making it comprehensive and interpretable. On the one hand, technological advancements have contributed to more extensive volumes of data, which are more challenging and complex to handle. On the other hand, the larger the data sets are, the higher the chances of finding relevant insights.
Data mining techniques
Let's start with the math and statistic core techniques. Later we will discover how these core techniques are evolving to advanced analytics regarding machine learning models and artificial intelligence.
1. Classification
Classification can retrieve valuable and relevant information from the data. As the name suggests, this analysis classifies data into distinct classes according to attributes or characteristics that data elements may share.
2. Association
This data mining technique considers particular attributes that are significantly correlated with another attribute. For instance, imagine we are executing a data analysis for a supermarket. The association rules highlight that if consumers buy gin, then they also buy tonic water, showing that these items are associated.
Therefore, association analysis helps to identify relations between variables in databases. Moreover, association rules can sometimes be used by data scientists and developers to build artificial intelligence programs.
3. Tracking Patterns
Tracking patterns is one the most basic (yet, precious) data mining techniques. In addition to identifying patterns within data sets, it can also monitor alterations in trends over time, allowing businesses to make intelligent decisions.
4. Outlier detection
In addition to identifying patterns, it is also essential to know if the data has outliers (or anomalies), which may provide actionable and valuable insights. Simply put, this technique shows items that significantly differ and are distant from other data points within a data set. Sometimes it means that measurement or data entry error is occurring (or has occurred) and should quickly be fixed; other times, it can be an opportunity to explore.
5. Regression
Regression analyses are used to identify relationships among variables. It is a technique applied to understand how a dependent variable can be predicted and influenced by the independent variable. For instance, imagine we own an e-commerce platform, and we want to improve our customers' satisfaction. Our dependent variable is "Customer Satisfaction," and our independent variable is "Page Speed". Executing regression analyses would allow us to understand how "Customer Satisfaction" can vary (increase or decrease) according to faster or slower "Page Speed".
In this example, we consider one dependent variable and one independent variable; thus, this is a Simple Regression Analysis. However, if we wanted to introduce more independent variables, then it would be a Multiple Regression Analysis. For instance, how is "Customer Satisfaction" (dependent variable) influenced by "Page Speed" and "Aesthetics" (independent variables).
Therefore, regression analyses are used to examine the relationship between variables and the overall strength of that relationship.
6. Clustering
Clustering is a technique used to discover groups (also named clusters) in the data. This process is somehow similar to the association technique, but it groups data according to the objects' similarities or what they have in common. Therefore, objects are similar to each other within a particular group.
Machine learning systems can use clustering techniques to group items from large data sets, dividing the data points into several clusters. In fact, clustering in ML is a technique that can be used to fulfill different purposes. For instance, discovering homogeneous groups (or clusters) can reduce data complexity, but it can also be used to discover unusual data objects and identify outliers. In ML clustering, the algorithm makes assumptions according to the similarities between data points, and according to these assumptions, it constitutes what is (or is not) a valid cluster.
There are several types of clustering algorithms a data scientist or a developer can choose to handle data sets in machine learning:
- Centroid-based clustering
- Graph-theory-based clustering
- Grid-based clustering
- Density-based clustering
- Partitioning-based clustering
- Distribution-bases clustering
- Model-based clustering
- Hierarchical clustering.
The list of types of clustering is quite extensive and could continue. These are just some of the most popular ones. When deciding which clustering algorithm to apply, it is important to consider how different approaches will scale the dataset in question.

Advanced Analytics and Data Mining
Advanced data analytics allows businesses and organizations to retrieve valuable insights from data sets. It is vital to identify trends, make predictions, optimize outcomes, and understand the variables that might influence a business.
Data mining is a crucial method within advanced analytics to discover patterns, trends, and anomalies. This method is based on scientific and mathematical methods.
In addition to encompassing data mining, advanced analytics also relies on business intelligence (BI), machine learning (ML), predictive analysis, and other analytical categories. Over recent years, machine-driven techniques (e.g., deep learning) have increasingly been implemented to analyze data sets and identify correlations and patterns among data points.
Therefore, in addition to master data mining techniques, data scientists must also perform more complex analyses that require mathematical knowledge, as well as familiarity with computer coding languages (mainly Python and R language).
Keep reading to find out how neural networks and deep learning, Natural Language Processing (NLP), and dimensionality reduction are being used to improve advanced analytics' techniques and methods, especially when it comes to data mining.
Neural networks and deep learning
Neural networks (NNs) consist of computing systems composed by collected nodes that are connected and form a network. It is inspired by how information is assimilated and distributed through nodes in biological systems. In neural networks, each connection between nodes can pass down information to other nodes, as observed in the image below.
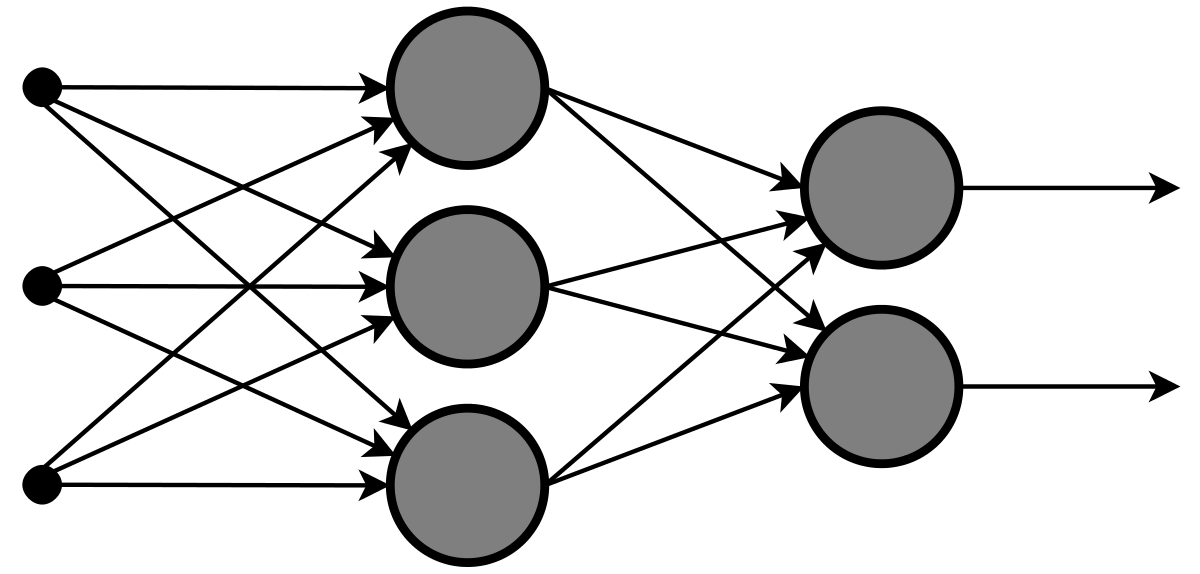
Neural networks help create better deep learning models for specific purposes. Regarding data mining techniques, neural networks can turn raw and unstructured data into relevant information by identifying patterns. Using this technique enables users to accumulate information from datasets to make more informed decisions through neural network’s ability to learn and deal with complex relationships. Consequently, this allows users to make informed and efficient decisions.
Considering neural networks for data mining, PyTorch and TensorFlow are among the most popular tools for this purpose.
Natural Language Processing (NLP)
Very simply put, natural language processing (NPL) is how computers are taught to understand how we - humans - communicate. It is a subfield of artificial intelligence (AI) that aims to read, interpret, manipulate and understand human languages.
NLP is an AI technology that can convert unstructured texts (in human languages) into structured data to be analyzed or drive machine learning algorithms. However, this is actually a text mining technique.
Text mining is a part of data mining, but it is not the same. On the one hand, the transformation from unstructured textual data to structured data is a text mining technique. On the other hand, data mining focuses on analyzing large data sets to identify patterns and relevant information. Once that data is turned into a structured format (by relying on text mining techniques), other data mining techniques can also be implemented to retrieve meaningful information.
Dimensionality reduction
Dimensionality reduction is a technique used to reduce a data-set from high-dimensional space to low-dimensional space in order to reduce the number of input variables in the dataset and remove not essential information from a data set. Sometimes, there might exist some redundant information that is not relevant to what needs to be analyzed. This occurs mainly in large data sets, where dimensionality reduction becomes particularly useful to handle complexity and ensure reliable insights.
There are several possible methods when conducting dimensionality reduction, such as Principal Component Analysis (PCA) and t-Stochastic Neighbor Embedding (t-SNE).
- The PCA is a mathematical procedure that reduces dimension while simultaneously preserving variability (as much as possible) by finding new variables (Principal Components) that are linear combinations (based on correlation or covariance matrix) of the existent variables in the original dataset.
- The t-SNE is a statistical method that allows the visualization of high-dimensional data sets by attributing a location to each data point within a 2D or 3D map.
Dimensionality reduction is a vital part of data mining. Due to technological advancements, there is a consequent need to handle data sets with massive volumes of data. Hence high-dimensional data is increasingly becoming more common and complex. Reducing it allows data scientists to analyze relevant information while retaining the meaningful properties from the original data set.
Conclusion
Data mining is about identifying patterns and retrieving valuable insights from collected data. As the article highlights, there are several data mining techniques a data scientist can employ. The first ones (classification, association, tracking patterns, and outlier detection) are a great way to start performing the essential tasks of data mining. Despite their simplicity, these techniques already provide very relevant and useful information for any business or organization.
Regression and clustering are also important data mining techniques. While regression identifies the relationships between variables; clustering, is extremely valuable to discover groups.
Considering the analytical advancements, our article also refers to the importance of data mining within advanced data analytics. We explain how neural networks, natural language processing, and dimensionality reduction can contribute to data mining. These skills will be precious for a data scientist, especially considering the technological progress we have been witnessing over the last years and how advanced technologies (AI and ML) are expected to shape the future.
