

Ein skalierbarer KI-Proof of Concept (PoC) ist ein experimentelles Projekt, das die Machbarkeit einer KI-Lösung demonstriert. Dabei werden die architektonischen Voraussichten und Infrastrukturaspekte berücksichtigt, die für eine zukünftige Erweiterung zu einem vollständigen Produktionssystem erforderlich sind. Es verifiziert das Potenzial eines KI-Modells und legt gleichzeitig die Grundlage für den Einsatz in der realen Welt.
Bei einem skalierbaren KI-PoC geht es darum, zu beweisen, dass es in großem Maßstab funktioniert, einen konsistenten Wert liefert und sich nahtlos in bestehende Geschäftsprozesse integrieren lässt. Es wandelt theoretisches Potenzial in greifbare, umsetzbare Lösungen um, die Wachstum und Effizienz fördern. Viele Unternehmen suchen nach umfassenden Lösungen KI-Lösungen für Unternehmen die innovativ und auch praktisch für großflächige Anwendungen sind.
Ein wirklich skalierbarer KI-PoC wurde vom ersten Tag an mit Blick auf die Produktion entwickelt. Dabei werden Faktoren wie Datenvolumen, Verarbeitungsgeschwindigkeit, Häufigkeit des Modellwechsels, Bereitstellungsumgebungen und Integrationspunkte mit anderen Systemen berücksichtigt. Es geht darum, eine solide Grundlage zu schaffen, die der erhöhten Belastung und Komplexität standhält, ohne dass später eine vollständige Neukonstruktion erforderlich ist.
Ein Standardprototyp konzentriert sich häufig ausschließlich auf die Demonstration der Kernfunktionen unter Verwendung begrenzter Daten und Ressourcen, oft in einer isolierten Umgebung. Es ist eine schnelle, schmutzige und effektive Methode, um eine Idee zu testen. Ein skalierbarer PoC geht jedoch noch weiter. Es beinhaltet:
Wichtigster Imbiss: Ein skalierbarer KI-PoC ist eine zukunftsorientierte Investition, die nicht nur das „ob“, sondern auch das „Wie“ und „zu welchen Kosten“ der breite Einsatz von KI-Lösungen innerhalb eines Unternehmens bestätigt.
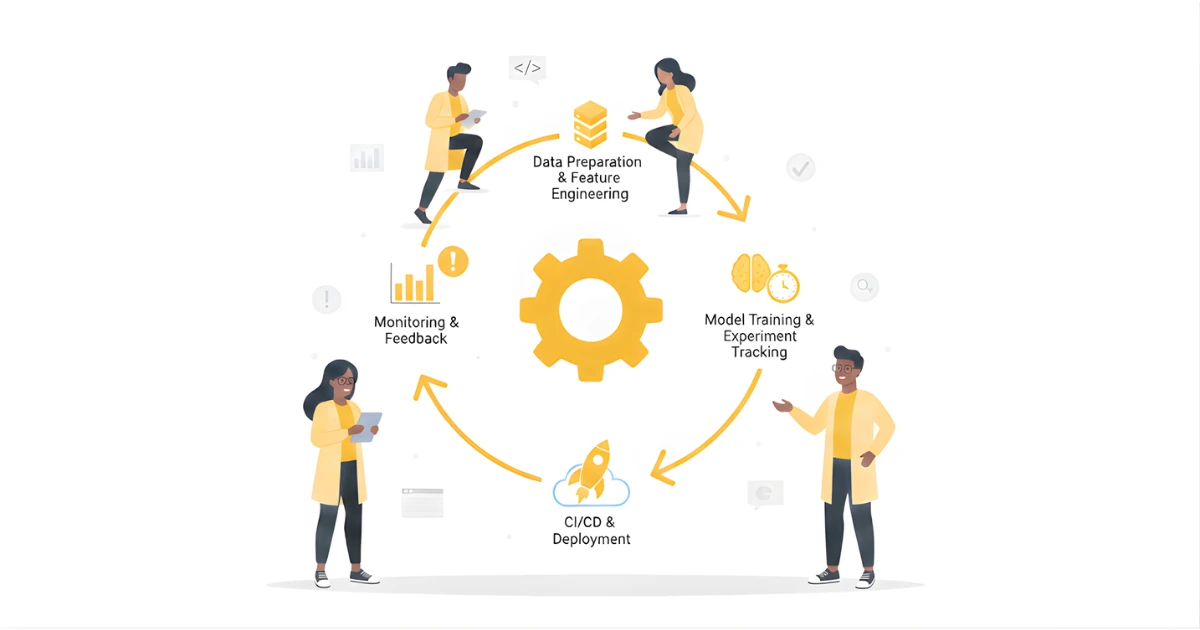
Der Aufbau einer robusten Pipeline für KI vom PoC bis zur Produktion stützt sich auf zwei wichtige Säulen: das Design einer skalierbaren Architektur und die Einrichtung robuster Datenpipelines. Wenn Sie diese frühzeitig vernachlässigen, kann dies zu erheblichen Engpässen und späteren Nacharbeiten führen.
Das Entwerfen einer skalierbaren KI-Architektur bedeutet, über das erste Experiment hinaus zu denken. Es beinhaltet Modularität, Microservices und Containerisierung.
Umsetzbare Schritte:
Daten sind das Lebenselixier jedes KI-Systems. Resiliente Datenpipelines gewährleisten einen kontinuierlichen, qualitativ hochwertigen Datenfluss für Training, Inferenz und Überwachung, auch unter Stress- oder Ausfallbedingungen.
Umsetzbare Schritte:
Wichtigster Imbiss: Eine produktionsreife KI-Lösung erfordert eine skalierbare Architektur, die auf Modularität und Cloud-Prinzipien basiert, gepaart mit automatisierten, validierten und belastbaren Datenpipelines.

MLOps (Machine Learning Operations) erweitert die DevOps-Prinzipien auf Workflows für maschinelles Lernen und schließt so die Lücke zwischen Datenwissenschaftlern und Betriebsteams. Die Implementierung von MLOPs Best Practices ist entscheidend für die Umstellung von KI-Modellen von der Forschung auf zuverlässige Produktionssysteme. Dazu gehören kontinuierliche Integration/kontinuierliche Bereitstellung (CI/CD) und eine robuste Überwachung.
Die Anwendung von CI/CD auf ML-Workflows beinhaltet die Automatisierung des gesamten Prozesses, von Codeänderungen über die Modellbereitstellung bis hin zur Neuschulung. Dies gewährleistet schnelle, konsistente und zuverlässige Updates.
Umsetzbare Schritte:
Modelle verschlechtern sich im Laufe der Zeit aufgrund sich ändernder Datenmuster oder realer Dynamiken. Kontinuierliche Überwachung und Optimierung sind unerlässlich, um die Leistung aufrechtzuerhalten.
Umsetzbare Strategien:
Wichtigster Imbiss: MLOps ist durch automatisierte CI/CD-Pipelines und kontinuierliche Überwachung das Rückgrat einer erfolgreichen KI-Modellproduktion und stellt sicher, dass Modelle leistungsfähig und relevant bleiben.
Die Entscheidung, ob eine interne MLOps-Plattform aufgebaut oder externe Dienste genutzt werden sollen, ist eine wichtige strategische Entscheidung bei der Skalierung von KI. Dieses Dilemma zwischen „Bauen und Kaufen“ wirkt sich auf die Ressourcenallokation, die Markteinführungszeit und die langfristige Wartbarkeit aus.
Der Aufbau einer internen MLOps-Plattform bietet ein Höchstmaß an Anpassung und Kontrolle, ist jedoch ressourcenintensiv.
Erwägen Sie, intern zu bauen, wenn:
Herausforderungen: Hohe Anfangsinvestitionen in Entwicklung und laufende Wartung, die ein engagiertes Team von ML-Ingenieuren, DevOps-Spezialisten und Datenarchitekten erfordern.
Ein Paradebeispiel für eine erfolgreiche „Build“ -Strategie ist Zillows Transformation seiner ikonischen Zschätzen Tool zur Immobilienbewertung.
Cloud-Plattformen und Managed Services beschleunigen die Entwicklung und Bereitstellung von KI erheblich, indem sie vorgefertigte Infrastrukturen und Tools bereitstellen. Diese Plattformen abstrahieren einen Großteil der zugrunde liegenden Komplexität, sodass sich die Teams stärker auf die Modellentwicklung konzentrieren können.
Vorteile:
Viele Unternehmen erwägen Partnerschaften mit KI-Beratungsunternehmen um diese Plattformen effektiv zu nutzen.
Spezialisierte KI-PoC-Dienste wie Axiom der imaginären Wolke, sind darauf ausgelegt, das Risiko von KI-Investitionen zu verringern und einen klaren, validierten Weg zur Produktion zu schaffen. Axiom ist ein Festpreis, 6 Wochen Prozess, der speziell für technische Führungskräfte, CTOs und technische Entscheidungsträger entwickelt wurde, die unternehmenskritische KI-Initiativen validieren müssen, bevor sie sich für die vollständige Entwicklung entscheiden.
Dieser „unternehmenstaugliche“ Ansatz sorgt dafür, dass der PoC vom ersten Tag an Skalierbarkeit, Wartbarkeit und Sicherheit bietet und die technischen Schulden eines Standardprototyps vermieden werden.
So beschleunigt Axiom Ihre KI-Reise:
Wichtigster Imbiss: Die Entscheidung „Bauen oder Kaufen“ hängt von Ihren individuellen Bedürfnissen, verfügbaren Ressourcen und strategischen Prioritäten ab. Cloud-Plattformen bieten Geschwindigkeit und Skalierbarkeit, während ein spezialisierter Service wie Axiom einen beschleunigten, risikoarmen und unternehmensgerechten Weg vom Konzept bis zum produktionsvalidierten PoC bietet.
Technische Exzellenz allein reicht für eine erfolgreiche KI-Skalierbarkeit nicht aus. Organisatorische Ausrichtung, kulturelle Bereitschaft und starke Governance-Rahmenbedingungen sind ebenso wichtig, um sicherzustellen, dass KI-Lösungen einen nachhaltigen Geschäftswert bieten.
Eine erfolgreiche Einführung von KI erfordert die Unterstützung des gesamten Unternehmens, von den Führungskräften bis hin zu den Mitarbeitern an vorderster Front. Die Förderung einer „KI-fähigen“ Kultur umfasst Kommunikation, Bildung und Zusammenarbeit.
Umsetzbare Schritte:
Mit der Skalierung der KI steigen auch ihre potenziellen Auswirkungen. Die Festlegung klarer Unternehmensführung und ethischer Richtlinien ist für einen verantwortungsvollen Einsatz von größter Bedeutung.
Kritische Überlegungen:
Wichtigster Imbiss: Neben den technischen Details hängt eine erfolgreiche KI-Skalierung von einer starken Ausrichtung der Führung, einer unterstützenden Organisationskultur und proaktiven ethischen und Governance-Rahmenbedingungen ab.
Der Übergang eines KI-Modells von einem kontrollierten Prototyp zu einer dynamischen Produktionsumgebung bringt mehrere komplexe Herausforderungen mit sich. Die Antizipation und Planung dieser Hürden ist für eine reibungslose und effektive Skalierung unerlässlich.
Dies sind einige der häufigsten und kritischsten Herausforderungen in der Produktions-KI:
Viele KI-Projekte schaffen es aufgrund einiger wiederkehrender Fallstricke nicht über das Labor hinaus:
Wichtigster Imbiss: Das proaktive Management von Daten und Modellabweichungen in Kombination mit einer produktionsorientierten Denkweise und einer starken funktionsübergreifenden Zusammenarbeit ist entscheidend, um die inhärenten Herausforderungen der Skalierung von KI zu bewältigen.
.webp)
Die Übertragung eines KI-Konzeptnachweises in eine skalierbare Produktionsumgebung ist eine komplexe und lohnende Reise. Dies erfordert einen großartigen Algorithmus und eine strategische Mischung aus robuster Architektur, sorgfältigen MLOp-Praktiken, durchdachten Build-vs-Buy-Entscheidungen und einer starken organisatorischen Abstimmung.
Indem Unternehmen sich auf die praktische Umsetzung, kontinuierliche Überwachung und proaktive Bewältigung von Herausforderungen konzentrieren, können sie das volle Potenzial ihrer KI-Initiativen ausschöpfen und Innovationen in nachhaltigen Geschäftswert umwandeln.
Sind Sie bereit, Ihre KI-Vision zu validieren und das Risiko Ihrer Investition zu verringern?
Der Weg vom Konzept zur Produktion ist die kritischste Phase der KI-Entwicklung. Kontaktiere uns um zu wissen, wie man Axiom AI PoC-Dienst, ein sechswöchiges Projekt zum Festpreis, das für technische Führungskräfte konzipiert wurde, um einen produktionsreifen Plan für ihre unternehmenskritischsten KI-Initiativen zu testen, zu validieren und zu erstellen.
Nach einem erfolgreichen KI-PoC gehören zu den wesentlichen Schritten die Verfeinerung des Modells für die Produktion, die Entwicklung skalierbarer Datenpipelines, die Einrichtung von MLOps für CI/CD, das Design für Überwachung und Umschulung sowie die Sicherung der Zustimmung der Interessengruppen für den vollständigen Einsatz.
Um ein KI-Modell von einem Jupyter Notebook in die Produktion zu überführen, sollten Sie zunächst den Notebookcode in modulare, produktionsreife Skripte umgestalten. Dann containerisieren Sie das Modell und seine Abhängigkeiten (z. B. mit Docker), implementieren Sie die Versionskontrolle, integrieren Sie es in CI/CD-Pipelines und stellen Sie es in einer skalierbaren Infrastruktur wie einem Cloud-verwalteten Dienst oder einem Kubernetes-Cluster bereit.
Eine Checkliste für eine erfolgreiche Produktion von KI-Modellen umfasst in der Regel: Sicherstellung der Datenqualität und Verfügbarkeit, Entwurf einer skalierbaren Architektur, Implementierung von MLOps CI/CD, Einrichtung einer kontinuierlichen Überwachung von Abweichungen und Leistung, Einrichtung automatisierter Umschulung, Sicherung der Infrastruktur, Berücksichtigung ethischer und behördlicher Bedenken sowie Planung der Geschäftsintegration und Benutzerakzeptanz.
Ein verwalteter MLOps-Service bietet sofort einsatzbereite Plattformen und Expertensupport für die Verwaltung von Infrastruktur, Tools und Best Practices, was die Bereitstellung beschleunigt und den Betriebsaufwand reduziert. Der Aufbau einer internen Lösung erfordert erhebliche Investitionen in die Entwicklung und Wartung Ihrer eigenen Plattform. Sie bietet ein Höchstmaß an Anpassungsfähigkeit, erfordert jedoch umfangreiches internes Fachwissen und Ressourcen.


Alexandra Mendes ist Senior Growth Specialist bei Imaginary Cloud und verfügt über mehr als 3 Jahre Erfahrung in der Erstellung von Texten über Softwareentwicklung, KI und digitale Transformation. Nach Abschluss eines Frontend-Entwicklungskurses erwarb Alexandra einige praktische Programmierkenntnisse und arbeitet nun eng mit technischen Teams zusammen. Alexandra ist begeistert davon, wie neue Technologien Wirtschaft und Gesellschaft prägen. Sie liebt es, komplexe Themen in klare, hilfreiche Inhalte für Entscheidungsträger umzuwandeln.
People who read this post, also found these interesting:










-%20Survey%20Insights.webp)



.webp)

.webp)

.webp)
.webp)










.webp)
.webp)
.webp)



.webp)

.webp)



.webp)


%20(1).webp)
.webp)









.webp)














.webp)


.webp)



.webp)


























